



SK
Size: a a a
2020 December 20
DT
в спарке планировщик делит ресурсы между джобами в пределах одного приложения
SK
Извиняюсь - удалёнка..
SK
Я в fair-sheduler.xml прописал очередь sample_queue
А у меня такого прилодения нет, а zeppelin не описан,поэтому он FIFO?
А у меня такого прилодения нет, а zeppelin не описан,поэтому он FIFO?
SK
Его туда прописать в место тестовых названия и скажем только очередь ограничить на 10 запрсов и хватит что ьы онивсе ресурсы использовал?
DT
чтобы цеппелин сабмитил джобы в очередь sample_queue, нужно это указать в его настройках
T
Привет накидайте докладов/статей по построению стриминговой архетуры, за последние годы. Которые вам понравились.
DT
ну то есть как
только для цеппелина
spark-submit MyApp --queue sample_queueтолько для цеппелина
SK
ну то есть как
только для цеппелина
spark-submit MyApp --queue sample_queueтолько для цеппелина
К сожалению мне ни о чём не говорит.. У меня всё по умолчанию было zeppelin - hadoop. Руководство захотело оптимизацию, так как некоторые задания отжирают все ядра и пытаюсь что-то сделать. Прописал в fair-sheduler.xml по образцу из доков sample_queue..
Её обязательно прописывать? Ведь такого приложения у меня нет, а есть zeppelin. Может убрать этот sample_queue и прописать zeppelin?
Её обязательно прописывать? Ведь такого приложения у меня нет, а есть zeppelin. Может убрать этот sample_queue и прописать zeppelin?
SK
Просто в 📄 доках этот sample_queue как пример, я так понял..
DT
ну это своеобразный выход, конечно
правильнее было бы явно указать, в какой очереди запускается цеппелин,
это можно сделать в настройках интерпретатора, указав в
правильнее было бы явно указать, в какой очереди запускается цеппелин,
это можно сделать в настройках интерпретатора, указав в
spark.yarn.queue имя очередиDT
либо через
https://community.cloudera.com/t5/Support-Questions/How-to-choose-the-queue-in-which-you-want-to-submit-the-job/td-p/168035
-Dspark.yarn.queue=my_zeppelin_queuenamehttps://community.cloudera.com/t5/Support-Questions/How-to-choose-the-queue-in-which-you-want-to-submit-the-job/td-p/168035
SK
Спасибо, изучу. В доках получается написано, очереди создаются (непонял этого из описания в доках Arenadata) , а для них как-то по разному приложения привязываются уже?
DT
это регулируется параметром
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/FairScheduler.html#Automatically_placing_applications_in_queues
yarn.scheduler.fair.user-as-default-queuehttps://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/FairScheduler.html#Automatically_placing_applications_in_queues
SK
Ага. Спасибо.
SK
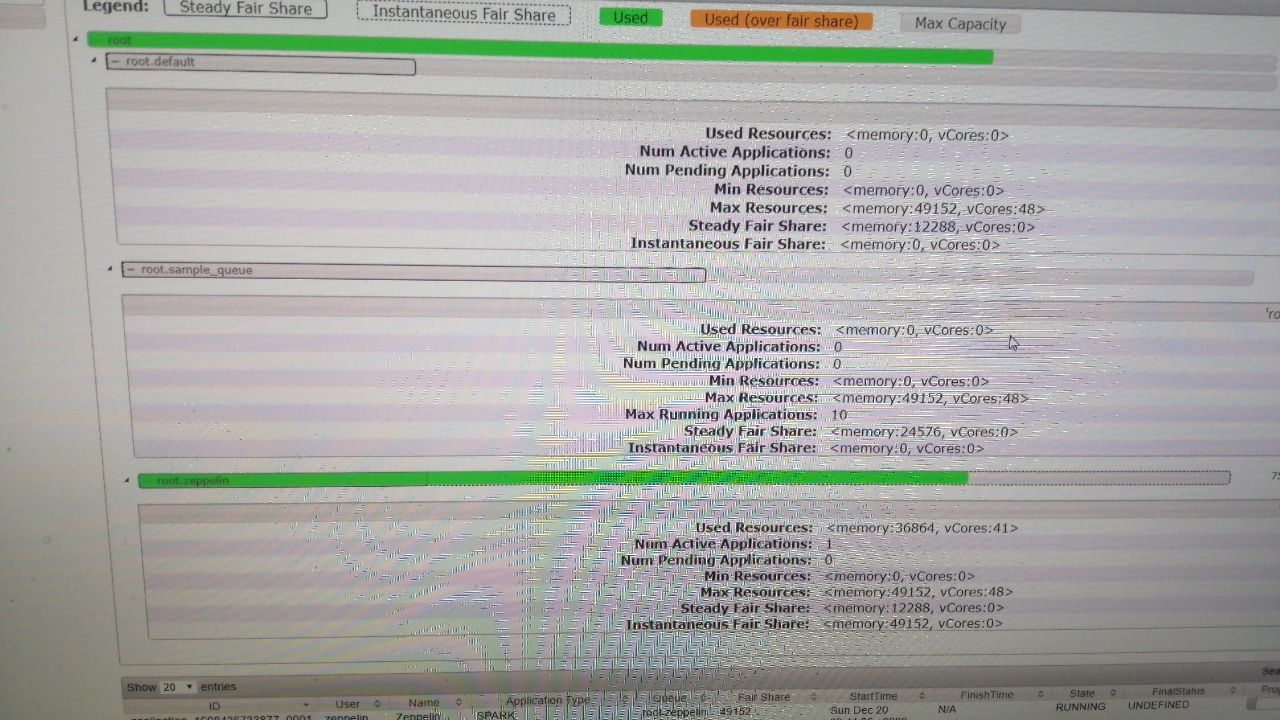
Смотрю на показатели в UI hadoop..
Зарезервирована память 42G
Используется 36G
Всего 48
Сам zeppelin почему-то 36G использует (раньше Memory Used 43 была..) Н-да
С ядрами так же..
Придётся ещё разбираться что да как.
Хорошо в FIFO можно быстро перевести обратно..
Зарезервирована память 42G
Используется 36G
Всего 48
Сам zeppelin почему-то 36G использует (раньше Memory Used 43 была..) Н-да
С ядрами так же..
Придётся ещё разбираться что да как.
Хорошо в FIFO можно быстро перевести обратно..
A
Пишешь на пайспарке, на все узлы кластера спарк ставишь необходимые библиотеки. Немного прийдется поизвращатся. Но работать будет. Можно даже расспаралелить обучение.
У пайспарка есть только модуль для ML, а для DL нету
Д
Можно пользоватся всеми библиотеками python.
A
Либо можно завернуть в virtualenv и забрасывать его на спарк-кластер
Очень интересно. Попытался погуглить и не смог найти примеров чтобы люди заворачивали ML/DL модели таким способом. Может вы знаете примеры?