ДН
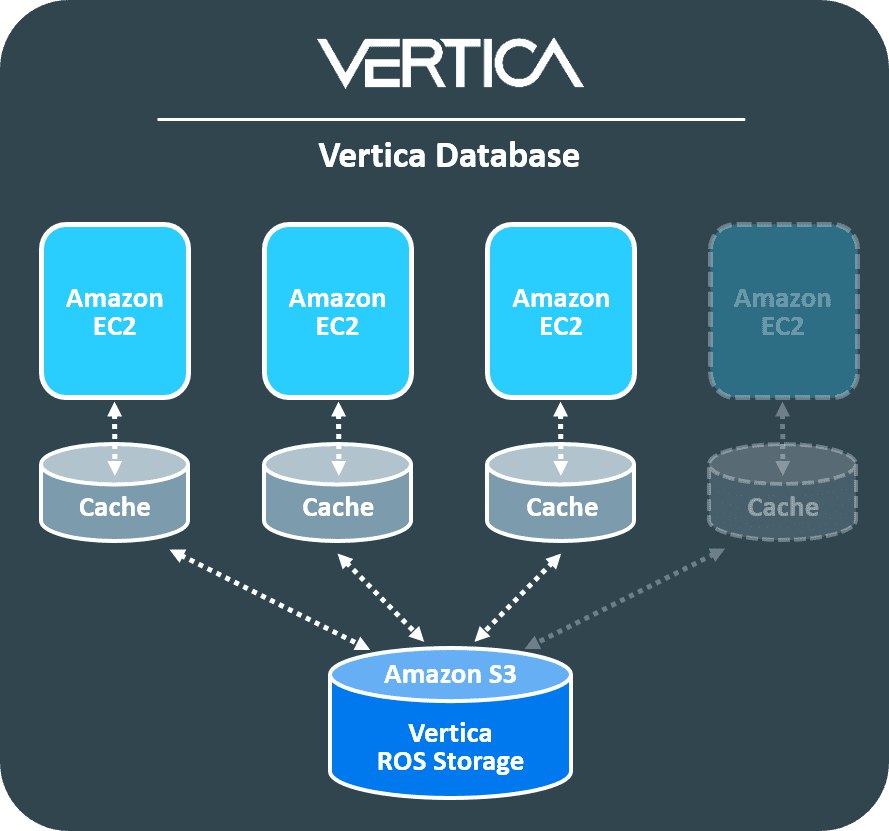
Вертика тоже вроде интересно в клауд-моде работает, хотя и писалась изначально под железки
Size: a a a
ДН
ИК
AT
AZ
AZ
AZ
AT
AZ
AE
AT
VP
AZ
AZ
А
spark.conf.set("spark.sql.join.preferSortMergeJoin", false)AG
spark.conf.set("spark.sql.join.preferSortMergeJoin", false)А
AG
А
AG
R
// Use ShuffledHashJoinExec's selection requirements
// 1. Disable auto broadcasting
// JoinSelection (canBuildLocalHashMap specifically) requires that
// plan.stats.sizeInBytes < autoBroadcastJoinThreshold * numShufflePartitions
// That gives that autoBroadcastJoinThreshold has to be at least 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1)