



Size: a a a
2019 August 06

Кстати всем спасибо, кто пришёл на митап из этого канала. Вы классные. Не со всеми успел поговорить, но много кого видел.
2019 August 07
Вчера увидел новую статью от Alexander Rush
И она по unsupervised суммаризации
Simple Unsupervised Summarization by Contextual Matching
Zhou et Rush [Harvard]
arxiv.org/pdf/1907.13337v1.pdf
И она по unsupervised суммаризации
Simple Unsupervised Summarization by Contextual Matching
Zhou et Rush [Harvard]
arxiv.org/pdf/1907.13337v1.pdf
#rl
Хорошие материалы по
TRPO:
1. medium.com/@jonathan_hui/rl-trust-region-policy-optimization-trpo-explained-a6ee04eeeee9
1. www.depthfirstlearning.com/2018/TRPO
1. spinningup.openai.com/en/latest/algorithms/trpo.html
DDPG:
1. towardsdatascience.com/deep-deterministic-policy-gradients-explained-2d94655a9b7b
1. yanpanlau.github.io/2016/10/11/Torcs-Keras.html
TDDDPG:
1. medium.com/aureliantactics/tensorflow-implementation-of-td3-in-openai-baselines-983a2ef384db
1. spinningup.openai.com/en/latest/algorithms/td3.html
Можете просто прочитать первую ссылку и соответсвующий алгоритму spinnigup. Должно стать сильно понятнее, чем до этого.
Хорошие материалы по
TRPO:
1. medium.com/@jonathan_hui/rl-trust-region-policy-optimization-trpo-explained-a6ee04eeeee9
1. www.depthfirstlearning.com/2018/TRPO
1. spinningup.openai.com/en/latest/algorithms/trpo.html
DDPG:
1. towardsdatascience.com/deep-deterministic-policy-gradients-explained-2d94655a9b7b
1. yanpanlau.github.io/2016/10/11/Torcs-Keras.html
TDDDPG:
1. medium.com/aureliantactics/tensorflow-implementation-of-td3-in-openai-baselines-983a2ef384db
1. spinningup.openai.com/en/latest/algorithms/td3.html
Можете просто прочитать первую ссылку и соответсвующий алгоритму spinnigup. Должно стать сильно понятнее, чем до этого.

2019 August 08
#rl
Сегодня занятия по RL не будет. Устроим голосовалку в чате, когда его провести.
Сегодня занятия по RL не будет. Устроим голосовалку в чате, когда его провести.
2019 August 09
Завтра в ШАДе у нас будет аж два события: семинар по RL и reading club по интерпретации BERT.
Я уже внёс в списки тех, кто участвует в summer camp, кто-то может добавиться ещё.
Время будет сообщено позже: ориентируйтесь на 12-15 часов.
Форма для охраны. Закроется в 12:00, торопитесь. Ещё у нас маленькая аудитория (Сорбонна, а не Оксфорд), надеюсь что вас будет не очень много)
https://forms.office.com/Pages/ResponsePage.aspx?id=DQSIkWdsW0yxEjajBLZtrQAAAAAAAAAAAAMAAKZ1i4JUQlBMQURTNFRIVksxT1lFUDBSUEgzQjdHQy4u
Я уже внёс в списки тех, кто участвует в summer camp, кто-то может добавиться ещё.
Время будет сообщено позже: ориентируйтесь на 12-15 часов.
Форма для охраны. Закроется в 12:00, торопитесь. Ещё у нас маленькая аудитория (Сорбонна, а не Оксфорд), надеюсь что вас будет не очень много)
https://forms.office.com/Pages/ResponsePage.aspx?id=DQSIkWdsW0yxEjajBLZtrQAAAAAAAAAAAAMAAKZ1i4JUQlBMQURTNFRIVksxT1lFUDBSUEgzQjdHQy4u

PyTorch 1.2 и TorchText 0.4 🎉
pytorch.org/blog/pytorch-1.2-and-domain-api-release
В PyTorch:
etc.
Поддержка tensorboard вышла из статуса экспериментальной. Просто используйте
pytorch.org/blog/pytorch-1.2-and-domain-api-release
В PyTorch:
nn.Transformer
nn.TransformerEncoder
nn.TransformerEncoderLayeretc.
Поддержка tensorboard вышла из статуса экспериментальной. Просто используйте
torch.utils.tensorboard
В torchtext завезли больше встроенных датасетов и туториалов и улучшили поддержку torch.data.dataset
Оказывается, у RASA есть свой research blog. Они попытались ускорить берт с помощью квантизации. Вообще довольно хорошая статья с обзором методов сжатия, почитайте.
Compressing BERT for faster prediction
blog.rasa.com/compressing-bert-for-faster-prediction-2
Спойлер: не смогли, но скорее всего всё дело в TF Lite
Compressing BERT for faster prediction
blog.rasa.com/compressing-bert-for-faster-prediction-2
Спойлер: не смогли, но скорее всего всё дело в TF Lite

Статьи, которые будут разобраны на reading club.
Кто хочет прийти - почитайте.
Кто хочет прийти - почитайте.
Некоторые статьи по анализу того, как работает BERT. Наверное, неплохо было бы их разобрать.
Visualizing and Measuring the Geometry of BERT
arxiv.org/pdf/1906.02715.pdf
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
arxiv.org/abs/1902.01007
Probing Neural Network Comprehension of Natural Language Arguments
arxiv.org/abs/1907.07355
How multilingual is Multilingual BERT?
arxiv.org/pdf/1906.01502.pdf
BERT Rediscovers the Classical NLP Pipeline
arxiv.org/abs/1905.05950
What Does BERT Look At? An Analysis of BERT's Attention
arxiv.org/abs/1906.04341
Visualizing and Measuring the Geometry of BERT
arxiv.org/pdf/1906.02715.pdf
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
arxiv.org/abs/1902.01007
Probing Neural Network Comprehension of Natural Language Arguments
arxiv.org/abs/1907.07355
How multilingual is Multilingual BERT?
arxiv.org/pdf/1906.01502.pdf
BERT Rediscovers the Classical NLP Pipeline
arxiv.org/abs/1905.05950
What Does BERT Look At? An Analysis of BERT's Attention
arxiv.org/abs/1906.04341
Завтра встречаемся по RL в 12
По reading club в 15:40
ШАД, Сорбонна
Будет организована трансляция на twitch, но не готов гарантировать, что она будет работать хорошо.
По reading club в 15:40
ШАД, Сорбонна
Будет организована трансляция на twitch, но не готов гарантировать, что она будет работать хорошо.
Гайд по тому, как конвертировать модели из TF в PyTorch от, наверное, самой опытной в этом команды - 🤗
Переходите на 🔥сторону.
medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28
Переходите на 🔥сторону.
medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28

2019 August 10
NLP reading club starts

2019 August 11

Всвязи с окончанием курса по #rl . Было весело.
2019 August 14
На архиве появилась какая-то дичь. Новый лосс для обучения генерации текста. Выглядит интересно.

Facebook. Connecting people.
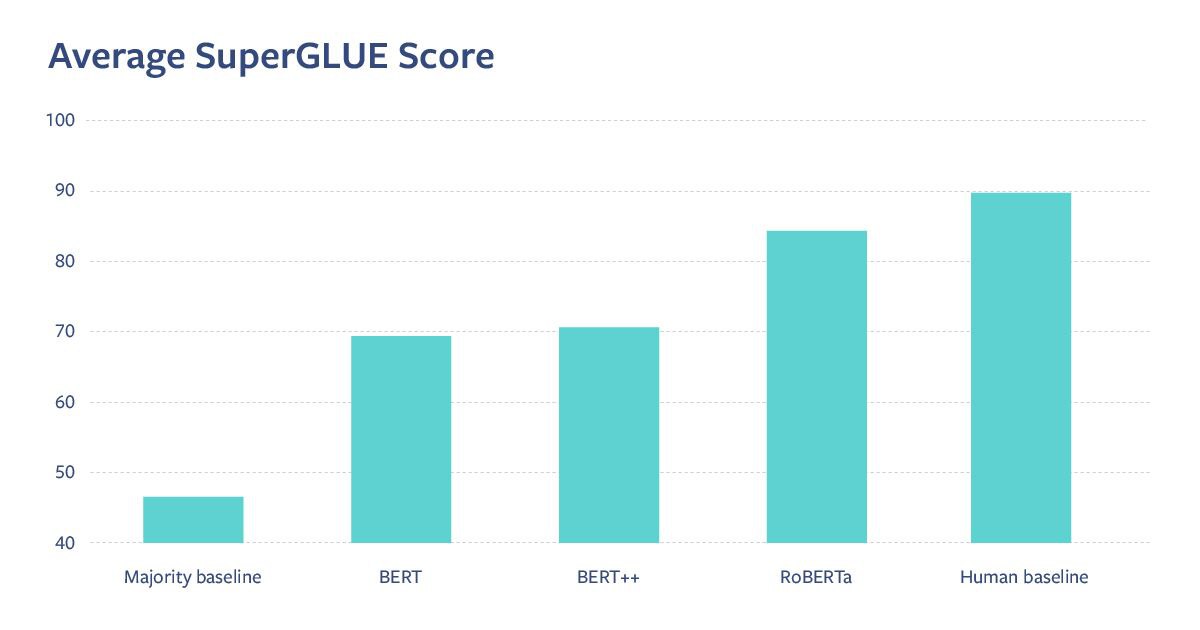
Пост про их успехи в машинном переводе, RoBERTA и SuperGLUE
ai.facebook.com/blog/new-advances-in-natural-language-processing-to-better-connect-people
Пост про их успехи в машинном переводе, RoBERTA и SuperGLUE
ai.facebook.com/blog/new-advances-in-natural-language-processing-to-better-connect-people
2019 August 15
How to Fine-Tune BERT for Text Classification?
Sun et al. Fudan University
arxiv.org/pdf/1905.05583.pdf
В статье пытаются смешать BERT и ULMfit. Получается довольно средне, но в конце концов они обходят ULMfit на почти всех датасетах (хоть и не сильно). В статье много хаков и мало убедительных ablation studies, но это best we have. На удивление мало статей, рассказывающих о том, как правильно применять BERT.
Sun et al. Fudan University
arxiv.org/pdf/1905.05583.pdf
В статье пытаются смешать BERT и ULMfit. Получается довольно средне, но в конце концов они обходят ULMfit на почти всех датасетах (хоть и не сильно). В статье много хаков и мало убедительных ablation studies, но это best we have. На удивление мало статей, рассказывающих о том, как правильно применять BERT.