Тут в чате говорят,
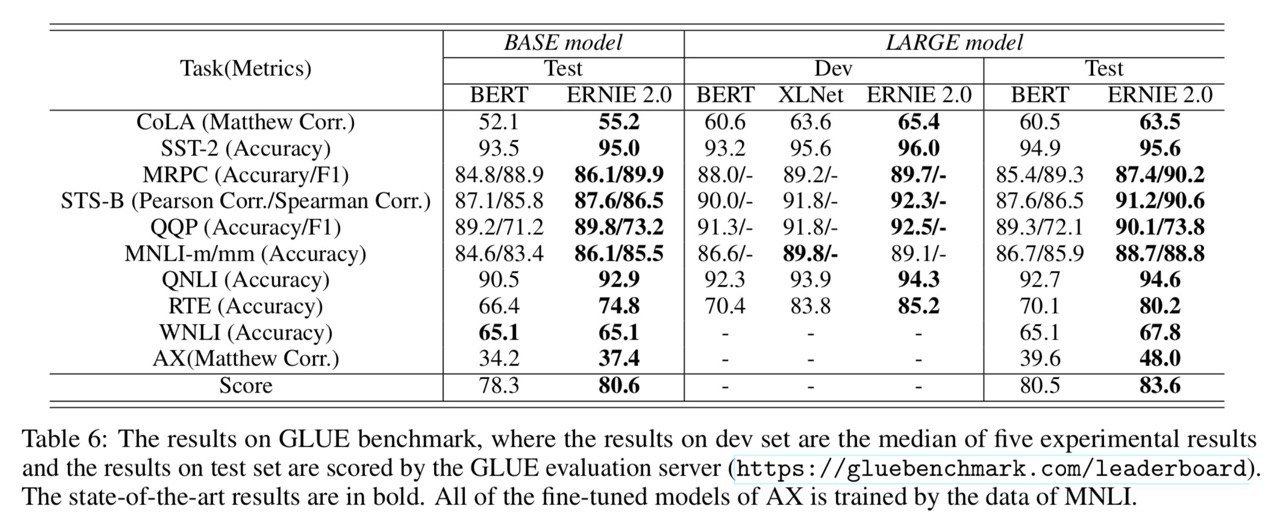
новую соту завезли 🎉 (на самом деле нет, RoBERTa всё равно лучше на GLUE).
Но если серьёзнее, то Baidu (не путать с Badoo) Research несколько дней назад представила свою модель ERNIE (Enhanced Representation through kNowledge IntEgration) 2.0.
Идея метода предобученния состоит примерно в следующем:
0. Толстый трансформер (как и у всех)
1. Continual pre-training: сразу несколько self-supervised (или weak-supervised) задач на уровне слов, синтаксиса и семантики
2. ERNIE стартует с одной из этих задач и постепенно во время обучения добавляются новые, более сложные
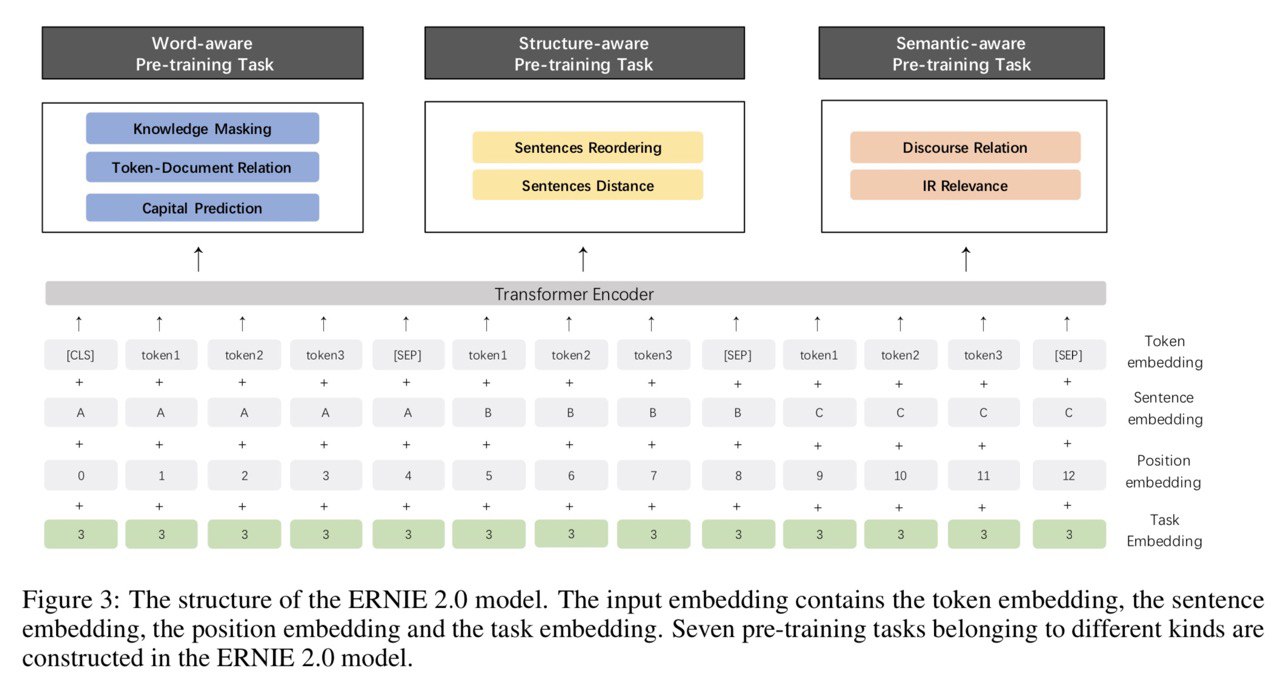
3. К каждому слову добавляется специальный эмбеддинг в зависимости от задачи
Подробнее про задачи:
1. Word-aware Pre-training Tasks:
1.1
Knowledge Masking - masked language model++, в котором маскируются фразы и именованные сущности, подробнее в статье про ERNIE 1.0
1.2
Capitalization Prediction - да, просто предсказывать, является ли это слово капитализированным. Забавная идея.
1.3
Token-Document Relation Prediction - предсказывается, появляется ли данное слово хотя бы ещё раз в данном документе. Тоже очень интересная идея - таким образом можно пытаться извлекать ключевые слова.
2. Structure-aware Pre-training Tasks
2.1
Sentence Reordering - N предложений случайно шаффлятся, после чего нужно предсказать их оригинальный порядок.
2.2
Sentence Distance - классификация пар предложений на три класса: идут подряд / находятся в одном документе / находятся в разных документах
3. Semantic-aware Pre-training Tasks
3.1
Discourse Relation - если я правильно понял, то это дисстиляция semantic relation модели
3.2
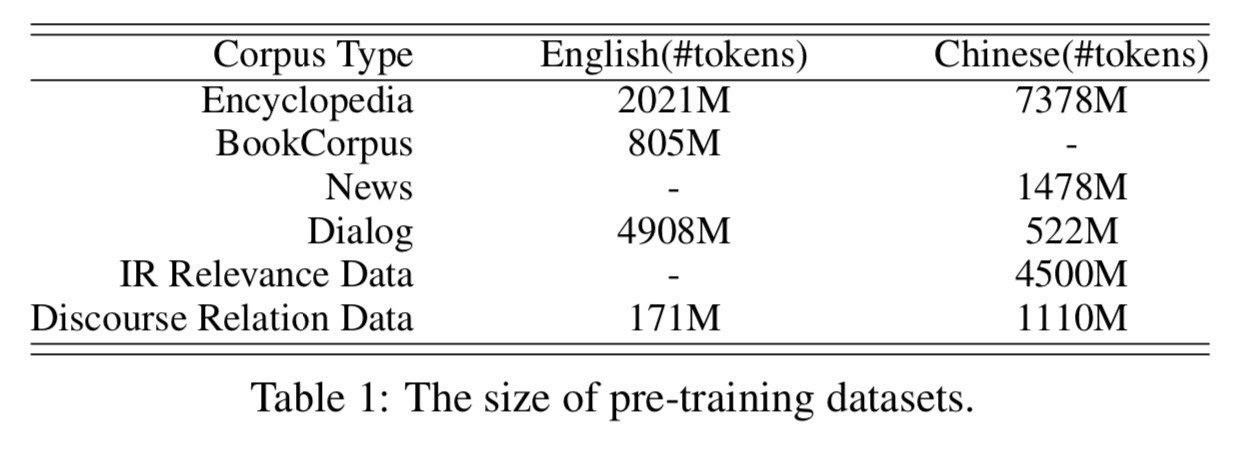
IR Relevance - тк Baidu это поисковик, у них есть логи поиска. Они и используются в этой задаче. По query и title нужно предсказать один из трёх классов: 0 - the title is clicked by the users after they input the query, 1 - these titles appear in the search results but failed to be clicked by users, 2 - the query and title are completely irrelevant
за ссылку на статью спасибо
@Cookie_thiefСтатья довольно неплохо написана, советую почитать
UPD: нету абляционных исследований 😫
ERNIE 2.0: A Continual Pre-Trainining Framework for Language Understanding
Sun et al. [Baidu]
arxiv.org/pdf/1907.12412v1.pdf