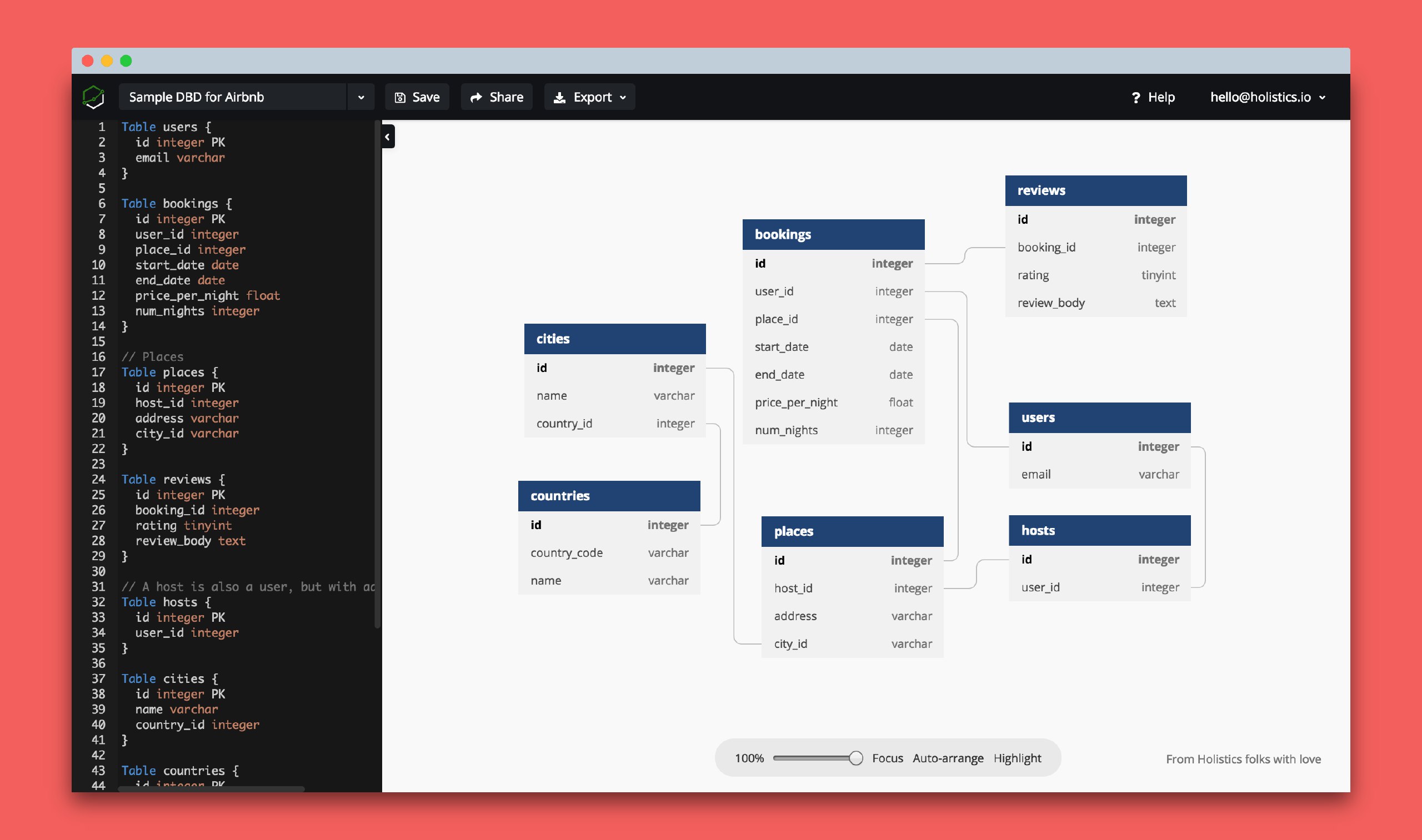
я, честно говоря, не уверен, что я правильно организовал структуру базы. Или правильно использую join. Чудовищно медленно получается по 4 секунды на запрос
Ну, тогда шли структуру, запрос и время выполнения.
Что за ин-флюс я конечно не знаю, но если это реляционная БД, это не важно