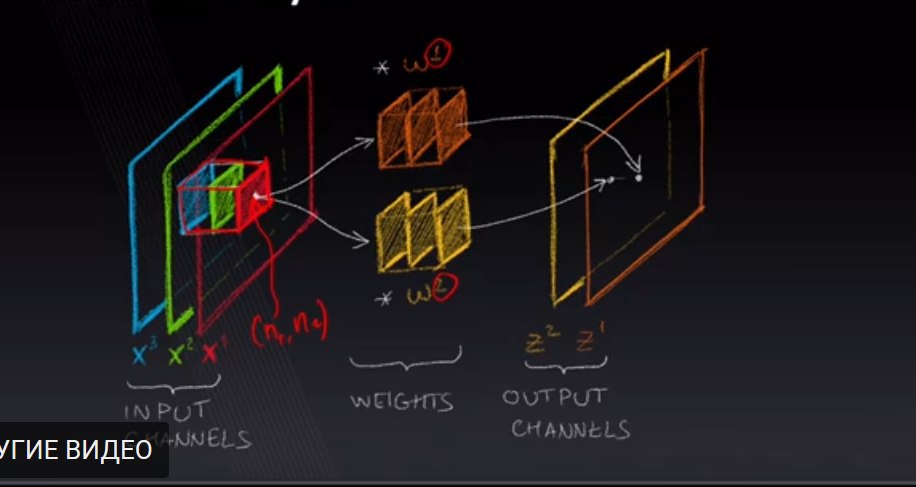
небольшой вопрос относительно CNN:
XW=Z
если Х это тензор, измерение которого (3,10,10) - 3 channels, each channel a matrix (10,10) (i.e image), каких измерений тензор W ?
Правильно ли думать о конволюции в данном случае, как о произведение XW=Z, где W по сути 4-ых мерный тензор, где первое измерение это количество фильтров (w1, w2, ..., w_n, например в данном случае случае n=2), или произведение тензоров это не так математически ?
Можете написать любые легальные значения для измерений тензора W и Z в данном случае для понимания ?
И кстати на данном рисунке берется кусочек, это типо batch-a всего датасэта, это на практике картинка, или несколько картинок или какой-то участок одной из картинок (которые сеть, в данном случае пусть будет один лаер учиться распознавать) ?
То есть процесс конволюции примерно такой:
Проходим по всем таким батчам, умножаем на четырех-мерный тензор, то есть set наших фильтров, получаем для каждого "батча" аутпут из того-же количества как и фильтров (это количество hyperparameter)