а нужно ли использовать preprocessing.scale () после нормализации, если уже привели все в диапазон от 0-1 https://take.ms/Csgtv на хабре просто используют для чего не понимаю, какой смысл использовать сначала нормализацию а потом стандартизацию
а нужно ли использовать preprocessing.scale () после нормализации, если уже привели все в диапазон от 0-1 https://take.ms/Csgtv на хабре просто используют для чего не понимаю, какой смысл использовать сначала нормализацию а потом стандартизацию
Нормализация и стандартизация это разные вещи. Нормализация загоняет все данные в диапазон, а стандартизация подразумевает такую предобработку данных, после которой каждый признак имеет среднее 0 и дисперсию 1
нет, можно и для каждого слова доставать векторы, почитай доки. ничто не мешает развернуть, например, на flask свою версию эмбеддингов, кстати
Мне не нужно разворачивать "на flask свою версию эмбеддингов" мне нужно запустить совой скрипт. Я могу это сделать с Docker + Flask? В чём будет отличие от bert-as-service?
Мне не нужно разворачивать "на flask свою версию эмбеддингов" мне нужно запустить совой скрипт. Я могу это сделать с Docker + Flask? В чём будет отличие от bert-as-service?
Как именно ты развернешь сервис - не важно. Важно , чтобы у тебя был доступный endpoint, по которому ты сможешь ходить и спрашивать числовые признаки для текста.
Всем привет Вопрос не про мл но все же , в оракле при лефт джойне некоторые записи дублируются а некоторые нет , с чем это может быть связано может есть кто сталкивался
Всем привет Вопрос не про мл но все же , в оракле при лефт джойне некоторые записи дублируются а некоторые нет , с чем это может быть связано может есть кто сталкивался
Потому что это лефт джоин, и во второй таблице где-то есть наллы
Я просто редко чекаю, и последние 2 раза, обсуждение образования идет
Один раз позволил себе роскошь не вмешиваться, и пожалел. Но виновные уже забанены, и повторять такое обсуждение черевато. Не знаю про какие два раза вы :) вероятно вот этот наш диалог и есть второе обсуждение уже давно закрытой темы
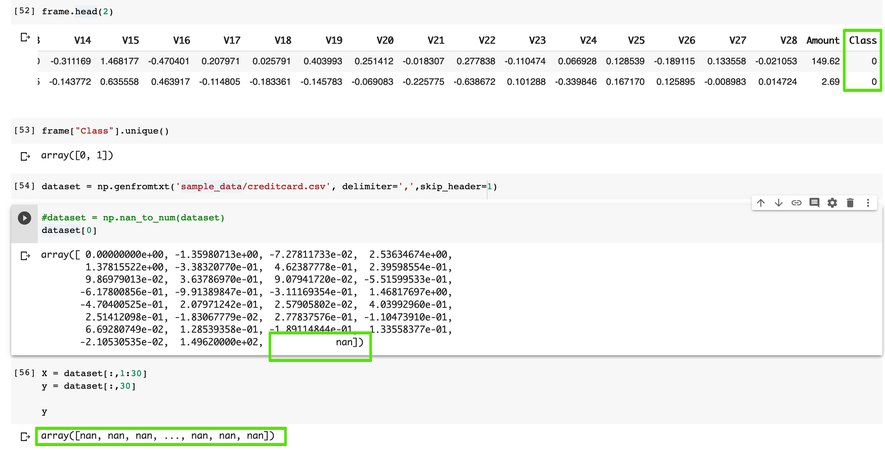
сначала посмотрел на данные черезх pandas, последний столбик идет как признак принадлежности к классу. Он бинарный 0 или 1. Далее гружу все через numpy: np.genfromtxt и вместо 0 и 1 вижу nan. Что нужно сделать? Подскажите пожалуйста
Всем привет! Кто-нибудь может порекомендовать хороший учебник по Deep Learning? Классика жанра от Goodfellow часто критикуется и говорится, что там масса информации про историческое развитие отрасли, вместо нужных данных, это правда?
сначала посмотрел на данные черезх pandas, последний столбик идет как признак принадлежности к классу. Он бинарный 0 или 1. Далее гружу все через numpy: np.genfromtxt и вместо 0 и 1 вижу nan. Что нужно сделать? Подскажите пожалуйста