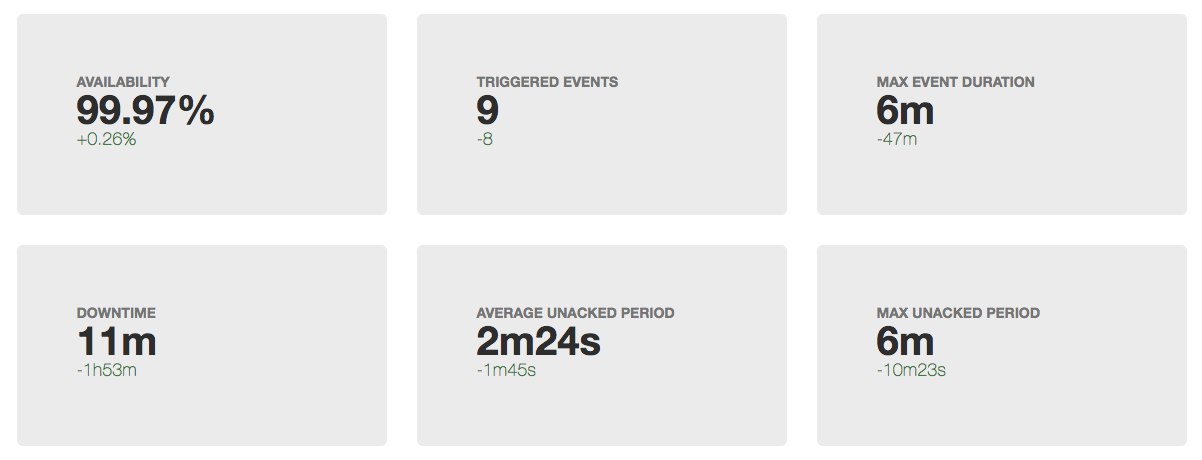
Конкретно у нас за это всё чудо отвечает Jira. При инцидентах мы создаём в ней таски на дежурного(админа/дба/сетевика/девелопера_который_лил_в_монолит_свой_код_и_на_2_дня_автоматически_залетел_на_дежуство/любого_бедалагу_который_по_какой-то_причине_оказался_в_списке_дежурных_какой-либо_команды), в эти таски мы аттачим скрины графиков, логи, ссылки на предыдущие схожие таски, описания, инфу о состоянии дочерних зааффекченных метриках. И всё это дублируем в личку в Slack, добавляя туда кнопку "Acknowledge"(если на триггере описана эскалация), чтобы нашим ребятам небыло необходимости лазить в вебморду нашей системы алертинга.