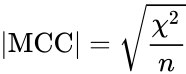ROC-кривые использовать на несбалансированных выборках - нормальная тема и не является суровой ошибкой. Они для этого и нужны, чтобы игнорировать дисбаланс. Проблема ROC-кривых в том, что они не различают классы по важности. ROC-кривые стоит использовать, если детекция обоих классов одинаково важна, просто так получилось, что у нас в выборке дисбаланс. Если же нас интересует детекция аномалий, то лучше, возможно, смотреть PR-кривые, но это на самом деле дело вкуса, потому что если модель доминирует в ROC-пространстве, то она доминирует и в PR (есть теорема). В целом, при отборе моделей, если классы разбалансированы, нужно считать не только ROC и PR, но и F1, сбалансированную точность и (альтернативный вариант специально для
@leria_k) корреляцию Мэтьюза. И не использовать что-то одно из этого, потому что максимизация ROC-AUC не ведет к максимизации PR-AUC автоматически (и наоборот, и так далее). Статью подробно не читал, но скорее всего авторы накосячили в том, что посчитали, раз ROC-AUC большой, то модель автоматически имба, что не так.