М
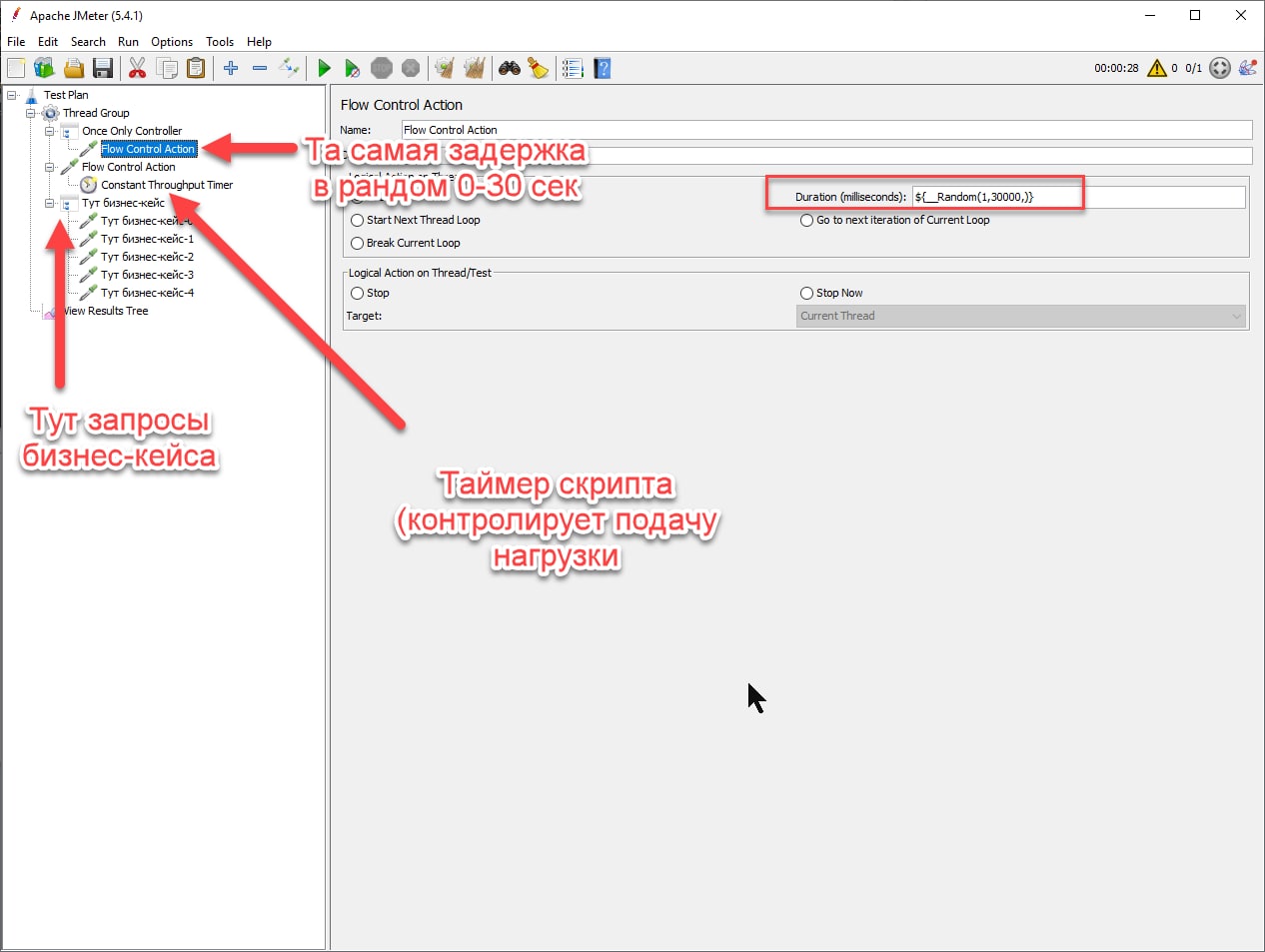
Спасибо, посмотрю. Пока просто вместо цикла for внутри thread группы сделал loop controller и в него csv data set config и beanshell воткнул. Вроде работает, но не уверен на счет эффективности такого метода в плане использования памяти и т д
Size: a a a
М
jj
VG
jj
VG
VG
ЮК
VG
VG
VG
VG
ЮК
VG
ЮК
ИФ
jj
ИФ