МК
Переслано от Вячеслав Смирнов...
Если с InfluxDB проблемы из-за большой базы данных, то можно поступить так:
1. Сделать отдельную новую базу данных.
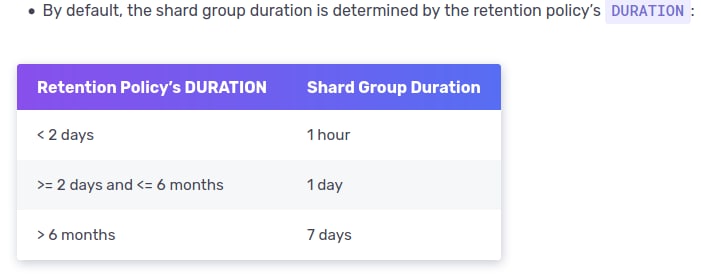
2. В ней сделать retention policy с временем жизни метрик 1 месяц. Только для оперативных метрик из JMeter. Такая база данных будет очень маленькой. Influxdb всю ее будет в памяти хранить. И работать быстро.
https://docs.influxdata.com/influxdb/v1.8/query_language/manage-database/#create-retention-policies-with-create-retention-policy
Так метрики будут сами удаляться из InfluxDB через месяц. Сравнивать два запуска средствами InfluxDB не получится уже, метрик не будет, останется только картинка - Grafana Snapshot. Но если сравнивать ничего не надо, то экономичный и простой вариант
1. Сделать отдельную новую базу данных.
2. В ней сделать retention policy с временем жизни метрик 1 месяц. Только для оперативных метрик из JMeter. Такая база данных будет очень маленькой. Influxdb всю ее будет в памяти хранить. И работать быстро.
https://docs.influxdata.com/influxdb/v1.8/query_language/manage-database/#create-retention-policies-with-create-retention-policy
CREATE RETENTION POLICY "one_month_only" ON "jmeter_database" DURATION 31d REPLICATION 1 DEFAULT3. А чтобы хранить историю отчетов использовать Grafana Snapshot-ы отчетов.
Так метрики будут сами удаляться из InfluxDB через месяц. Сравнивать два запуска средствами InfluxDB не получится уже, метрик не будет, останется только картинка - Grafana Snapshot. Но если сравнивать ничего не надо, то экономичный и простой вариант