



KY
но замечено его влияние на времена отклика, надо следить
Size: a a a
KY
KY
KY
s
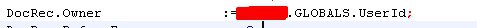
S7
K
KY
K
KY
KY
KY
K
K
KY
K
KY
TK
AK
total = from(bucket: "raw_gatling")
|> range(start: dashboardTime, stop: upperDashboardTime)
|> filter(fn: (r) => r._measurement == "requests" and r._field == "duration")
|> count(column: "_value")
|> drop(columns: ["_start", "groups", "name", "nodeName", "result", "simulation", "testId"])
|> sum()
|> duplicate(column: "_stop", as: "_time")
|> drop(columns: ["_stop"])
|> map(fn: (r) => ({
r with
_field: "requestCount"
}))
|> tableFind(fn: (key) => key._field == "requestCount")
|> getRecord(idx: 0)
from(bucket: "raw_gatling")
|> range(start: dashboardTime, stop: upperDashboardTime)
|> filter(fn: (r) => r._measurement == "requests" and r._field == "duration" and r.result == "KO")
|> count(column: "_value")
|> drop(columns: ["_start", "groups", "name", "nodeName", "result", "simulation", "testId"])
|> sum()
|> duplicate(column: "_stop", as: "_time")
|> drop(columns: ["_stop"])
|> map(fn: (r) => ({r with _value: float(v: r._value) / float(v: total._value) * 100.0}))ΙΤ
total = from(bucket: "raw_gatling")
|> range(start: dashboardTime, stop: upperDashboardTime)
|> filter(fn: (r) => r._measurement == "requests" and r._field == "duration")
|> count(column: "_value")
|> drop(columns: ["_start", "groups", "name", "nodeName", "result", "simulation", "testId"])
|> sum()
|> duplicate(column: "_stop", as: "_time")
|> drop(columns: ["_stop"])
|> map(fn: (r) => ({
r with
_field: "requestCount"
}))
|> tableFind(fn: (key) => key._field == "requestCount")
|> getRecord(idx: 0)
from(bucket: "raw_gatling")
|> range(start: dashboardTime, stop: upperDashboardTime)
|> filter(fn: (r) => r._measurement == "requests" and r._field == "duration" and r.result == "KO")
|> count(column: "_value")
|> drop(columns: ["_start", "groups", "name", "nodeName", "result", "simulation", "testId"])
|> sum()
|> duplicate(column: "_stop", as: "_time")
|> drop(columns: ["_stop"])
|> map(fn: (r) => ({r with _value: float(v: r._value) / float(v: total._value) * 100.0}))VG
total = from(bucket: "raw_gatling")
|> range(start: dashboardTime, stop: upperDashboardTime)
|> filter(fn: (r) => r._measurement == "requests" and r._field == "duration")
|> count(column: "_value")
|> drop(columns: ["_start", "groups", "name", "nodeName", "result", "simulation", "testId"])
|> sum()
|> duplicate(column: "_stop", as: "_time")
|> drop(columns: ["_stop"])
|> map(fn: (r) => ({
r with
_field: "requestCount"
}))
|> tableFind(fn: (key) => key._field == "requestCount")
|> getRecord(idx: 0)
from(bucket: "raw_gatling")
|> range(start: dashboardTime, stop: upperDashboardTime)
|> filter(fn: (r) => r._measurement == "requests" and r._field == "duration" and r.result == "KO")
|> count(column: "_value")
|> drop(columns: ["_start", "groups", "name", "nodeName", "result", "simulation", "testId"])
|> sum()
|> duplicate(column: "_stop", as: "_time")
|> drop(columns: ["_stop"])
|> map(fn: (r) => ({r with _value: float(v: r._value) / float(v: total._value) * 100.0}))