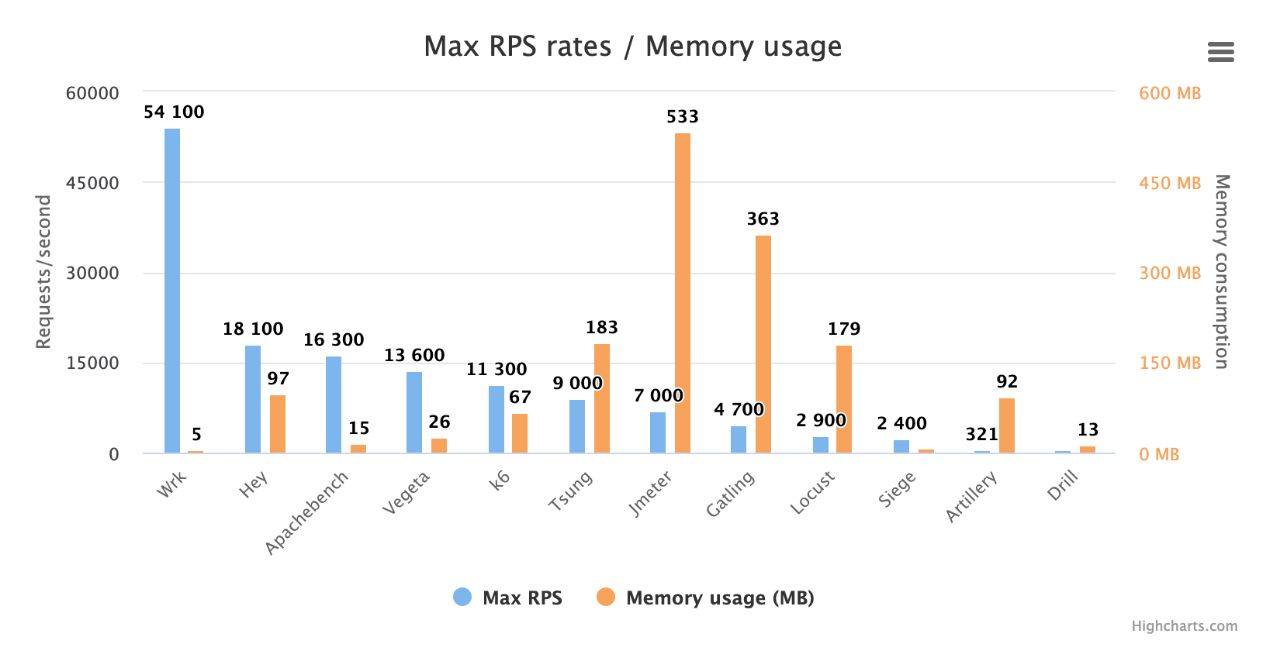
Другая причина для использования большого количества подключений. Чтобы проверить, что в цепочке
[JMeter] -> [nginx/haproxy] -> [app] -> [DB]
прокси в виде [nginx/haproxy] защищает [app] от большого количества подключений.
Подключение к [app] дорогое - много памяти.
Подключение к [nginx/haproxy] дешевле.
Поэтому и используют [nginx/haproxy], они держат соединения с клиентами, и через пул подключений, ограниченный сверху (пусть в 200), работают с [app]. Так стабильнее.
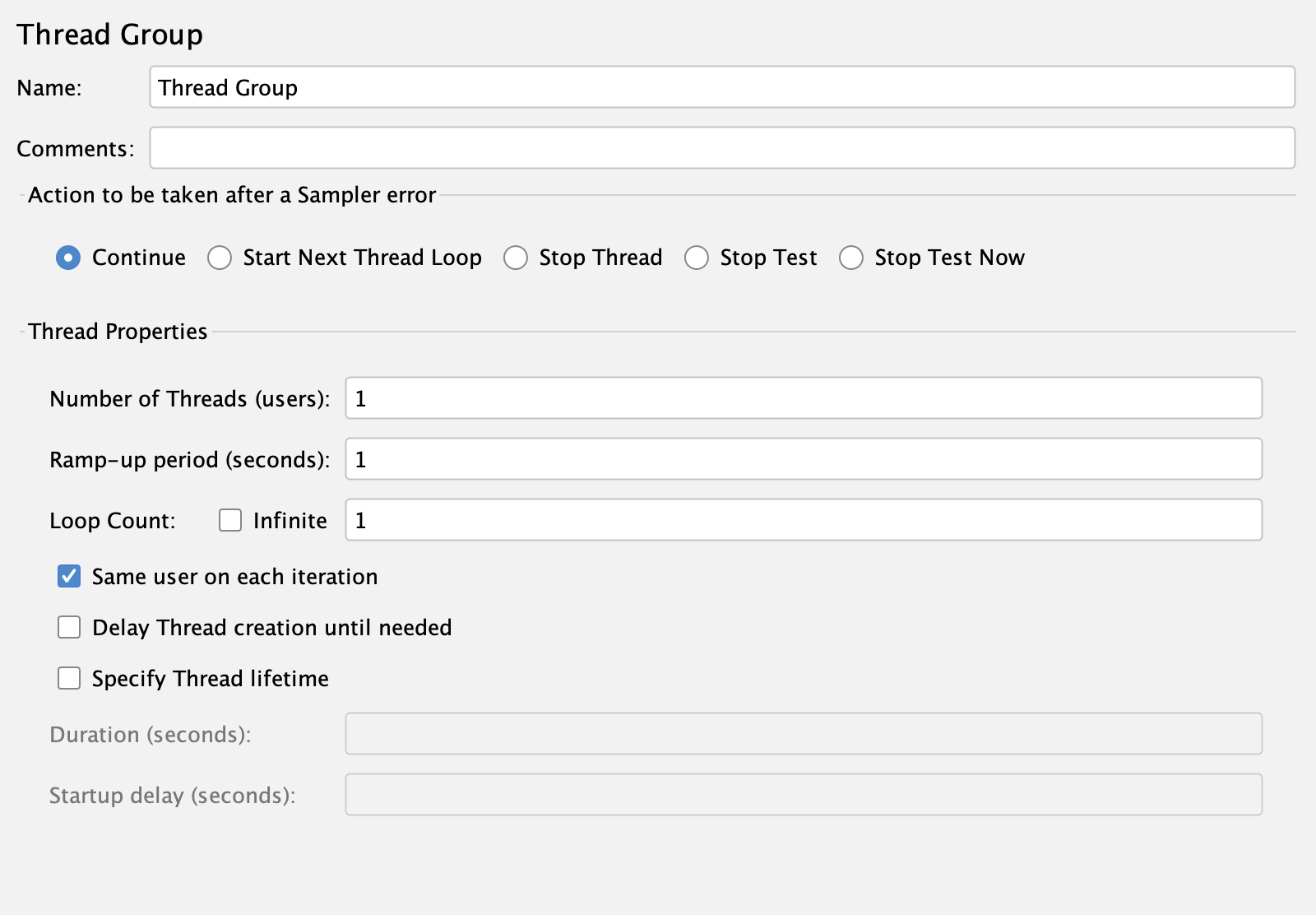
Для этого надо будет из [JMeter] создать много сессий. Много потоков.
Необходимо такое тестирование вот из-за чего. Бывает в [app] не ограничен пул, или ограничен в 2000 воркеров (много очень). И всё это работает только потому, что перед ним есть [nginx/haproxy], который допускает до [app] только 200 одновременных клиентов, и поэтому в [app] работает только 200 воркеров. И мы не получаем "Out of memory" в [app].
Но если ни [nginx/haproxy] ни [app] не настроены или в них "Для хорошей производительности" все настройки были выставлены в максимум.
А мы в инструменте [JMeter] создаём 10 подключений, вместо 1000, то мы никогда и не нагрузим систему.
Но это уже не очень связано с темой
«same user on each iteration»
Тут даже на сопоставлении 1 поток - 1 соединение можно сделать тысячи соединений, просто выставив в JMeter 1000 потоков.
Это написал для полноты.