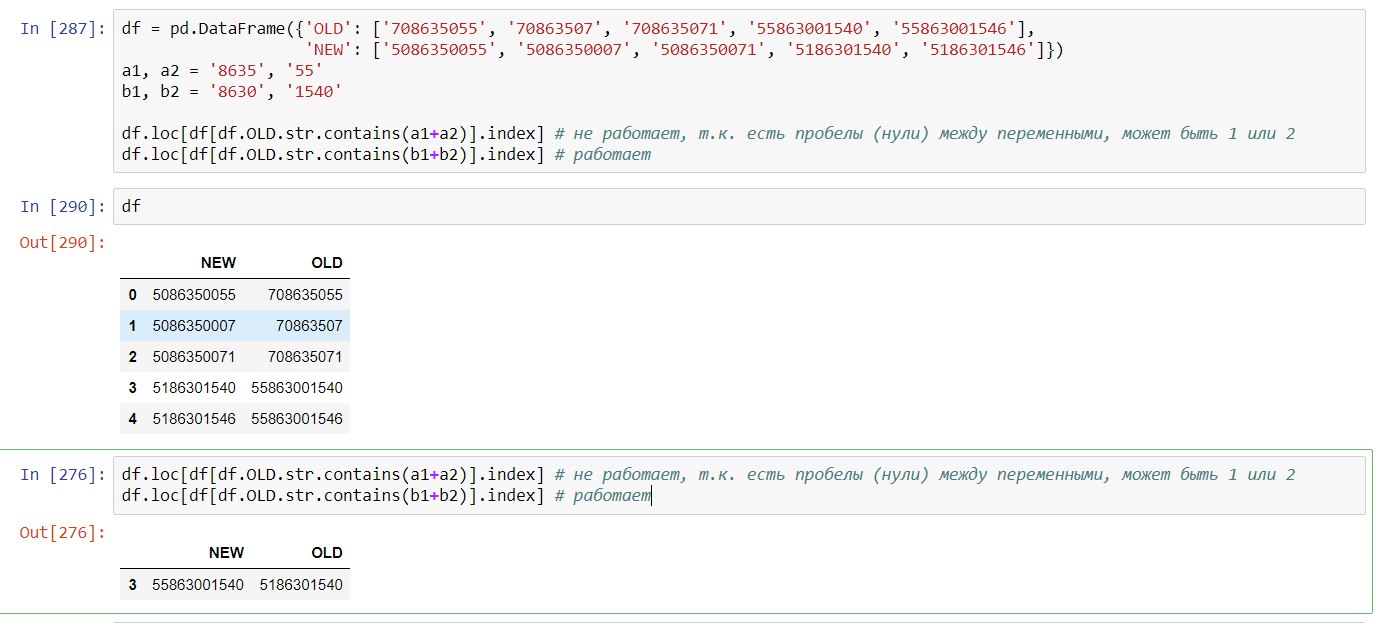
Ребята, привет. Помогите, пожалуйста с относительным поиском индекса по df. Понимаю, что тут нужны регулярки, но не понимаю как их пристроить. На скриншоте наглядно.
df = pd.DataFrame({'OLD': ['708635055', '70863507', '708635071', '55863001540', '55863001546'],
'NEW': ['5086350055', '5086350007', '5086350071', '5186301540', '5186301546']})
a1, a2 = '8635', '55'
b1, b2 = '8630', '1540'
df.loc[df[df.OLD.str.contains(a1+a2)].index]
df.loc[df[df.OLD.str.contains(b1+b2)].index]