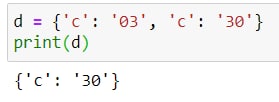
В первой части кода список со словарями:
ds = dataset[:2]
print
(ds)
Out:
[{'id': '66', 'stName': 'Новослободская'},
{'id': '67', 'stName': 'Менделеевская'}]
Поcле перебора id в POST-запросах получил JSON (изменил код для наглядности)
ds2 = []
for row in range(len(ds)):
settings = {'mod': 'metrobook', 'oper': 'getShortestPath',
'sdid1': from_station, 'sdid2': ds[row]['id'],
'mid': '2','whatToMinimize': '0'}
table = requests.post('https://metrobook.ru/kcmsajax.php', data=settings, headers=headers).json()
ds2.append(table['table'])
JSON с ответом по ID выглядит так:
print(table)
Out:
{'success': True,
'totalCount': 0,
'table': {'changeTime': 120,
'changeNumber': 1,
'transitTime': 1140,
'ans': [239, 238, 132, 206, 88, 101, 226, 225, 67],
'totalTime': 1260},
'errors': []}
Отсюда нужен только словарь table:
print(table['table'])
Out:
{'changeTime': 120,
'changeNumber': 1,
'transitTime': 1140,
'ans': [239, 238, 132, 206, 88, 101, 226, 225, 67],
'totalTime': 1260}
В цикле выше я добавил словарь table в отдельный список:
print(ds2)
Out:
[{'changeTime': 240,
'changeNumber': 1,
'transitTime': 1140,
'ans': [239, 238, 132, 206, 88, 86, 89, 91, 66],
'totalTime': 1380},
{'changeTime': 120,
'changeNumber': 1,
'transitTime': 1140,
'ans': [239, 238, 132, 206, 88, 101, 226, 225, 67],
'totalTime': 1260}]
Теперь нужно расширить словари в
ds словарями из
ds2. Это я и спрашивал выше , как объединить, т.к. не сообразил самостоятельно и сделал именно добавлением "по шагам".
Если использовать для этого pandas, наверное бы сделал по-другому. Сначала в ds2 добавил бы id по которому отправляю POST запрос, а потом:
df = pd.DataFrame(ds)
df2 = pd.DataFrame(ds2)
df3 = pd.merge(left=df, right=df2, on="id")