



AB
Size: a a a
2020 December 05
2020 December 06
YP
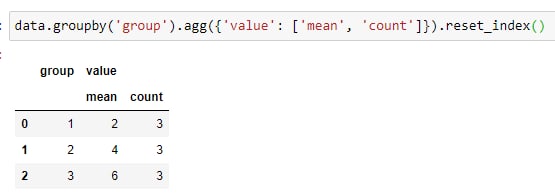
Салют! Есть таблица с двумя полями value и group, хочу получить также поля sum и count внутри каждой группы (по сути оконные функции в sql). Делаю group by и джоиню с изначальной таблицей. В целом работает, но выдает варнинги из за того, что при группировке получается такая таблица (которую я джоиню)
YP
Собственно, вопросы:
1. Как при нескольких агрегатных функциях получить таблицу со столбцами group, value, mean, count (где mean и count не будут под value)?
2. Возможно, есть изначально более правильный способ, чем мержить сгруппированную таблицу?
1. Как при нескольких агрегатных функциях получить таблицу со столбцами group, value, mean, count (где mean и count не будут под value)?
2. Возможно, есть изначально более правильный способ, чем мержить сгруппированную таблицу?
AO
transform
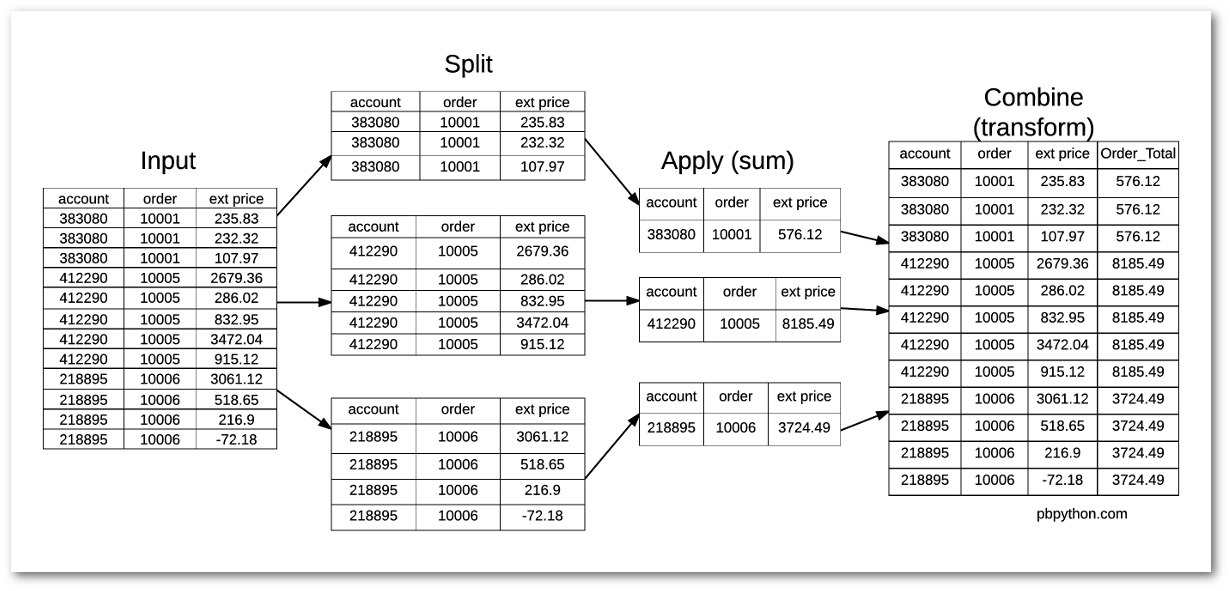
YP
Круто, спасибо!
2020 December 07
IS
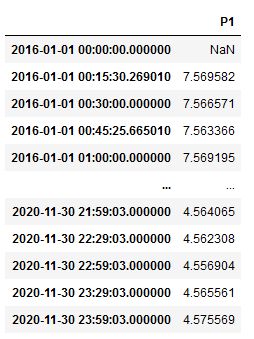
Здравствуйте! Мне надо оставить в датафрейме только значения, у которых в индексе есть XX:00:00 или XX:30:00, то есть значения через каждые 30 минут. Я создаю отдельный датафрейм с нужной мне периодичностью (30 минут), затем применяю update. В итоге все вроде бы ок. Но что-то мне подсказывает, что это немного кривое решение. Подскажите, пожалуйста, есть ли встроенные возможности для данной задачи. Поиск по интернетам не помог, либо я не умею задавать вопросы)
YP
Здравствуйте! Мне надо оставить в датафрейме только значения, у которых в индексе есть XX:00:00 или XX:30:00, то есть значения через каждые 30 минут. Я создаю отдельный датафрейм с нужной мне периодичностью (30 минут), затем применяю update. В итоге все вроде бы ок. Но что-то мне подсказывает, что это немного кривое решение. Подскажите, пожалуйста, есть ли встроенные возможности для данной задачи. Поиск по интернетам не помог, либо я не умею задавать вопросы)
Можно использовать filter
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.filter.html
Или же просто сделать reset_index и работать с этой колонкой как обычно.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.filter.html
Или же просто сделать reset_index и работать с этой колонкой как обычно.
IS
Можно использовать filter
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.filter.html
Или же просто сделать reset_index и работать с этой колонкой как обычно.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.filter.html
Или же просто сделать reset_index и работать с этой колонкой как обычно.
reset разве удалит ненужное?
YP
Нет, reset превратит индекс в обычную колонку, а там можно будет сделать что то типа
df[df['your_column'].str.contains(30:00)]
YP
Хотя, думаю, с датой можно как то более оптимально поступить. Мб кастануть к инту и смотреть на остаток от деления.
IS
Хотя, думаю, с датой можно как то более оптимально поступить. Мб кастануть к инту и смотреть на остаток от деления.
Вот я тоже думал, что есть какие-то специальные подходы к datetimeindex
ВК
конечно есть подходы)
ВК
в пандас отличный инструментарий для работы с временем
NN
Добрый день. Помогите, пожалуйста. Учусь на налитика, пишу проект, докопалась до задачи, которую не могу решить (
Есть датафрейм df1 с тремя колонками, например
A B C
1 10 25
2 15 6
3 20 89
4 25 3
5 25 20
6 20 67
7 116 89
8 7 34
Есть список - No с перечислением чисел, которые надо убрать из датафрейма, например no=[20, 25, 3]
Есть список - Yes с перечислением чисел, которые надо вставить вместо тех, которые надо убрать yes=[4, 777, 9]
То ли у меня глаза замылились и я не вижу очевидных вещей, то ли знаний не хватает.
Есть датафрейм df1 с тремя колонками, например
A B C
1 10 25
2 15 6
3 20 89
4 25 3
5 25 20
6 20 67
7 116 89
8 7 34
Есть список - No с перечислением чисел, которые надо убрать из датафрейма, например no=[20, 25, 3]
Есть список - Yes с перечислением чисел, которые надо вставить вместо тех, которые надо убрать yes=[4, 777, 9]
То ли у меня глаза замылились и я не вижу очевидных вещей, то ли знаний не хватает.
NN
Числа вставить надо в случайном порядке
KM
df = pd.DataFrame({'names':['vasya', 'petya', 'masha'], 'scores':[1,2, 3]})
to_replace = {1: 10, 2:20}
df['scores'] = df['scores'].replace(to_replace)
to_replace = {1: 10, 2:20}
df['scores'] = df['scores'].replace(to_replace)
KM
то есть из ваших двух списков No и Yes делаете 1 словарь
NN
df = pd.DataFrame({'names':['vasya', 'petya', 'masha'], 'scores':[1,2, 3]})
to_replace = {1: 10, 2:20}
df['scores'] = df['scores'].replace(to_replace)
to_replace = {1: 10, 2:20}
df['scores'] = df['scores'].replace(to_replace)
Благодарю! Всё получилось.