А
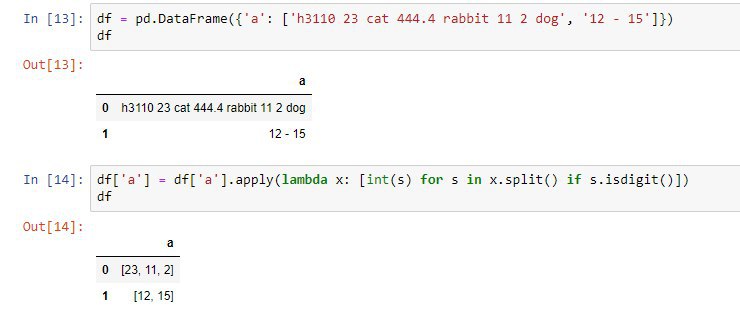
а в цикле проверить методом .isnumeric() и добавлять в лист, если True
Size: a a a
А
YP
R
R
YP
ВЛ
ВЛ

YP
YP
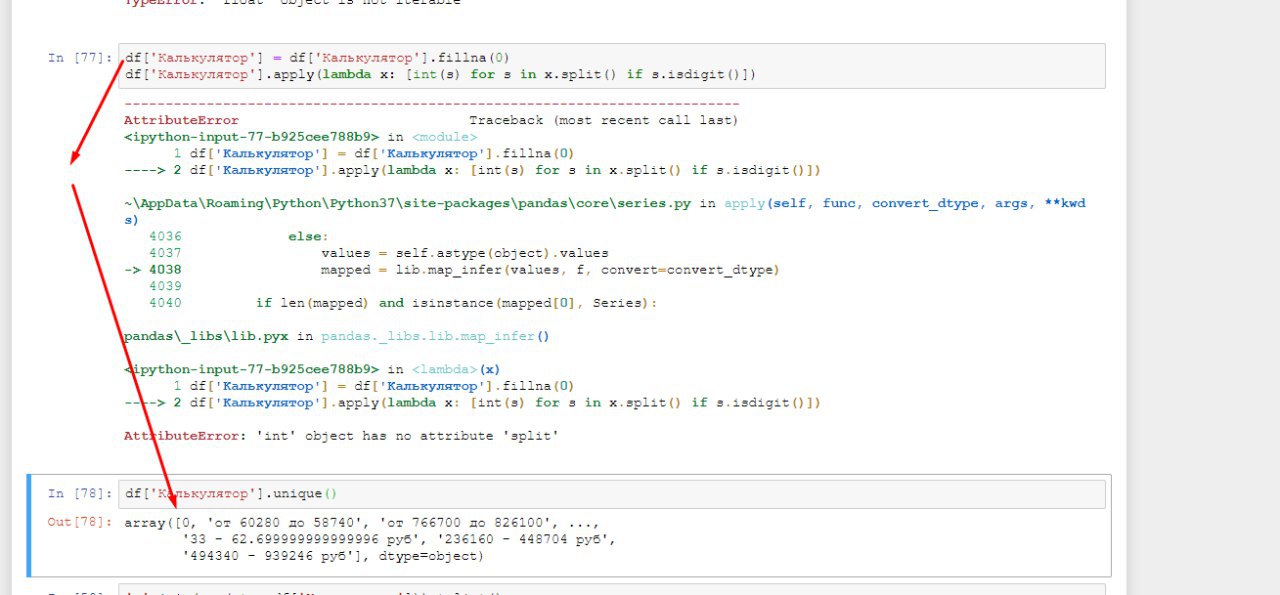
df['Калькулятор'] = df['Калькулятор'].fillna('')ВЛ
YP
YP
AP
ВЛ

YP
df['Калькулятор 3'] = df['Калькулятор 2'].apply(lambda x: np.mean(x)).fillna(0)
ВЛ
df['Калькулятор 3'] = df['Калькулятор 2'].apply(lambda x: np.mean(x)).fillna(0)
РЧ
AP
df = pd.DataFrame([[i for i in np.random.randint(1,100,10)] for z in range(1,5)])
for col in [i for i in df.columns if i!=0]:
df[str(col)+'_share'] = df[col]/df[0]
АМ
df = pd.DataFrame([[i for i in np.random.randint(1,100,10)] for z in range(1,5)])
for col in [i for i in df.columns if i!=0]:
df[str(col)+'_share'] = df[col]/df[0]