



OB
Size: a a a
2019 September 11
OB
все в таком формате
OB
Юрий решил эту задачу :) Спасибо :)
def xml_df(city, path):
path = path + city + '.xml'
dfcols = ['id', 'name' ,'available', 'price', 'dimensions']
root = et.parse(path)
rows = root.findall('.//offer')
xml_data = [[row.get('id'), row.find('name').text, row.get('available'), row.find('price').text,
row.find('dimensions').text] for row in rows if hasattr(row.find('dimensions'), 'text')]
xml_data.extend([[row.get('id'), row.find('name').text, row.get('available'), row.find('price').text,
''] for row in rows if not hasattr(row.find('dimensions'), 'text')])
df_xml = pd.DataFrame(xml_data, columns=dfcols)
return df_xml
MY
Юрий решил эту задачу :) Спасибо :)
def xml_df(city, path):
path = path + city + '.xml'
dfcols = ['id', 'name' ,'available', 'price', 'dimensions']
root = et.parse(path)
rows = root.findall('.//offer')
xml_data = [[row.get('id'), row.find('name').text, row.get('available'), row.find('price').text,
row.find('dimensions').text] for row in rows if hasattr(row.find('dimensions'), 'text')]
xml_data.extend([[row.get('id'), row.find('name').text, row.get('available'), row.find('price').text,
''] for row in rows if not hasattr(row.find('dimensions'), 'text')])
df_xml = pd.DataFrame(xml_data, columns=dfcols)
return df_xml
👍
2019 September 12
ЕБ
всем привет! а кто-нибудь занимался парсингом на сплинтере? интересует возможность деплоя этого на сервер
ВЛ
Привет! Скажите, пж, почему после перевода с текстового формата в дату и время, переводит неправильно,в том смылсе что добавляет дни и время?
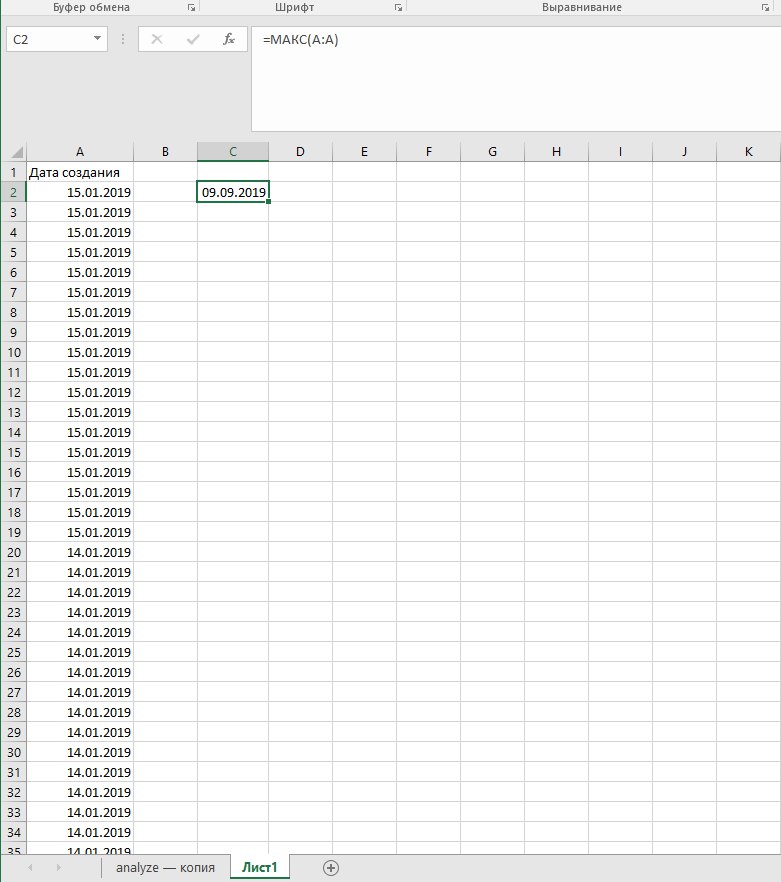
Максимальная дата и время в excel и в python не совпадают.
Скрин с excel http://prntscr.com/p5666d
Скрин с python http://prntscr.com/p565ot
Как мне превратить нормально?
Максимальная дата и время в excel и в python не совпадают.
Скрин с excel http://prntscr.com/p5666d
Скрин с python http://prntscr.com/p565ot
Как мне превратить нормально?
YP
Привет! Скажите, пж, почему после перевода с текстового формата в дату и время, переводит неправильно,в том смылсе что добавляет дни и время?
Максимальная дата и время в excel и в python не совпадают.
Скрин с excel http://prntscr.com/p5666d
Скрин с python http://prntscr.com/p565ot
Как мне превратить нормально?
Максимальная дата и время в excel и в python не совпадают.
Скрин с excel http://prntscr.com/p5666d
Скрин с python http://prntscr.com/p565ot
Как мне превратить нормально?
Используйте date_parser при загрузке файла
https://stackoverflow.com/questions/17465045/can-pandas-automatically-recognize-dates
https://stackoverflow.com/questions/17465045/can-pandas-automatically-recognize-dates

ВЛ
Используйте date_parser при загрузке файла
https://stackoverflow.com/questions/17465045/can-pandas-automatically-recognize-dates
https://stackoverflow.com/questions/17465045/can-pandas-automatically-recognize-dates

Спасибо! Немножко по другому сделал)
Но тут была подсказка
Но тут была подсказка
YP
Обращайтесь)
2019 September 13
V
Господа и дамы!
Очень нужна консультация хардкорного питониста со знаниями ETL-процессов и GBQ.
Буду признатален за помощь
Очень нужна консультация хардкорного питониста со знаниями ETL-процессов и GBQ.
Буду признатален за помощь
OO
Господа и дамы!
Очень нужна консультация хардкорного питониста со знаниями ETL-процессов и GBQ.
Буду признатален за помощь
Очень нужна консультация хардкорного питониста со знаниями ETL-процессов и GBQ.
Буду признатален за помощь
Вы бы хоть немного очертили предмет консультации. Без этого непонятно, что значит "хардкорный"
V
Закрытый сервер (оператор перс.данных, подотчётен ЦБ), работа со скриптом, который собирает данные, делает предварительный расчёты, логирует ошибки и выплевывет всё самое очищенное от любого намека на перс. данные в BQ
OO
Airflow смотрели?
V
Airflow смотрели?
Leider gibt es keine(((
V
Нет иными словами
2019 September 15
С
Leider gibt es keine(((
Немцы в городе 😀😜
С
Leider gibt es keine(((
Hände hoch! 😝😝😝
2019 September 16
A
Привет, есть небольшой массив, который сохраняется в эксельку
df1 = pd.DataFrame (vals)
df1.to_excel("vals1.xlsx", encoding='utf8')
Это дело живёт в Google.Colab - перестало записываться в файл. Может, у кого-то аналогичная беда?
df1 = pd.DataFrame (vals)
df1.to_excel("vals1.xlsx", encoding='utf8')
Это дело живёт в Google.Colab - перестало записываться в файл. Может, у кого-то аналогичная беда?
AG
Привет, есть небольшой массив, который сохраняется в эксельку
df1 = pd.DataFrame (vals)
df1.to_excel("vals1.xlsx", encoding='utf8')
Это дело живёт в Google.Colab - перестало записываться в файл. Может, у кого-то аналогичная беда?
df1 = pd.DataFrame (vals)
df1.to_excel("vals1.xlsx", encoding='utf8')
Это дело живёт в Google.Colab - перестало записываться в файл. Может, у кого-то аналогичная беда?
Не сталкивался, но когда нужно было читать/писать монтировал google.drive:
from google.colab import drive
drive.mount('/content/drive')
os.chdir("drive/My Drive/ML/TextGen")
A
Монтировал, всё ок, файлы там живут - я их вижу. Проверил генерацию массива - ок
Но в файл не пишется - никаких ошибок
Но в файл не пишется - никаких ошибок