



VM
Size: a a a
2021 December 02

VM
Может отсутствующая дата - причина ошибки?
А
🤦♂️реально. Я на саму дату даже не посмотрел, спасибо.
3
ylim, если ещё актуально)
AL
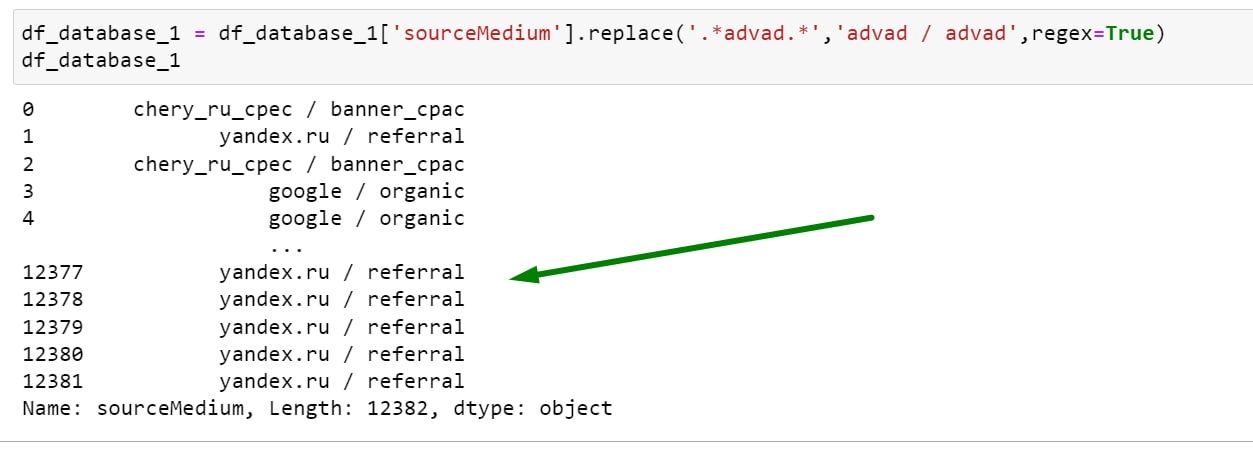
Добрый день, вопрос новичка, почему, когда я делаю замену таким образом, датафрейм перестает быть датафреймом
3
Вы присваиваете изначальному df_database_1 всего одну колонку из него? Если так и нужно, оберните ‘sourceMedium’ в ещё одни квадратные скобки
AL
нет мне просто в колонке нужно значение заменить, датафрейм должен остаться прежним
3
Тогда нужно не df_database_1 присваивать а df_database_1[‘sourceMedium’]
AL
так а у меня как
3
Ну или можно без присваивания обойтись с inplace’ом
AL
разве не так же
3
Нет)
Посмотрите внимательно:
У вас идёт df_database_1 = …
А нужно df_database_1[‘sourceMedium’] = …
Посмотрите внимательно:
У вас идёт df_database_1 = …
А нужно df_database_1[‘sourceMedium’] = …
AL
ааааа
AL
поняла ((( спасибо большое, не подумала, это первая операция с датфреймом, которую я пыталась провести ))) еще rename и query остались😂
М
Привет всем.
У меня есть DF с около 1млн строк примерно такого содержания:
df = pd.to_dataframe(data={
"col_1":[1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5],
"col_2":["a", "b", "a", "b", "a", "b", "c", "d", "a", "b", "c", "d", "c", "d"]
})
Нужно оставить такой результат. Убрать повторяющиеся вхождения.
df_res = pd.to_dataframe(data={
"col_1":[1, 2, 3, 4, 5],
"col_2":["a", "b", "c", "d", np.nan]
})
Подскажите пожалуйста, как можно это сделать?
У меня есть DF с около 1млн строк примерно такого содержания:
df = pd.to_dataframe(data={
"col_1":[1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5],
"col_2":["a", "b", "a", "b", "a", "b", "c", "d", "a", "b", "c", "d", "c", "d"]
})
Нужно оставить такой результат. Убрать повторяющиеся вхождения.
df_res = pd.to_dataframe(data={
"col_1":[1, 2, 3, 4, 5],
"col_2":["a", "b", "c", "d", np.nan]
})
Подскажите пожалуйста, как можно это сделать?
AG
df[‘col1’].unique()?
AG
А, нужно ещё для тех кого меньше nan
М
В общем у меня есть id - это col_1 и к ним подтянуты транзакции - это col_2.
Задача к каждой col_1 оставить одну транзакцию, при этом транзакция не должна упоминаться 2 раза
Задача к каждой col_1 оставить одну транзакцию, при этом транзакция не должна упоминаться 2 раза
AG
Так может ты мерж неправильно просто сделал?)