Если не нейронные сети, то какой-нибудь OCR на основе cкрытой марковской модели (Hidden Markov). Если и это сложно, то тогда даже не знаю, ни один аналитический алгоритм не будет обладать хоть сколь нибудь достоверной точностью
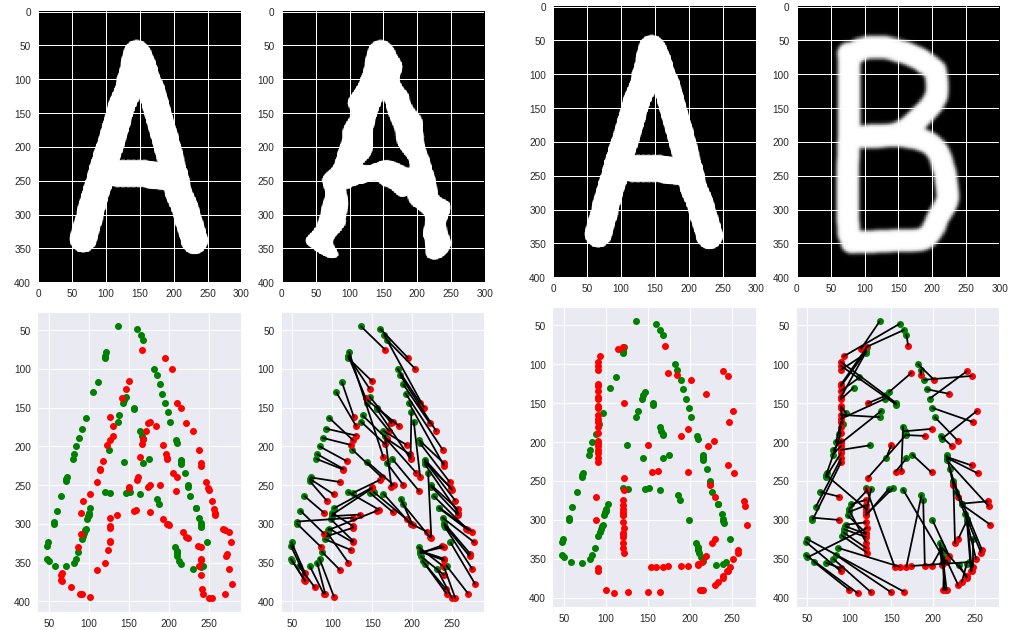
Ну, вообще можно, конечно, скелет построить, а потом учиться на скелете: его топологии и параметрах кривых между "суставами". Путь более сложный, с каждым шрифтом новые приключения. Но зато где-то можно время в рантайме сэкономить