LM
Так изменения параметра pool_size влияет на количество занятых коннектов?
Да, конечно влияет
Size: a a a
LM
D
LM
pg_stat_activity. Где статусы то idle, то idle in transactionMC
MC

YS
MC
MC
YS
MC
S
VY
MC
YS
YS
LM
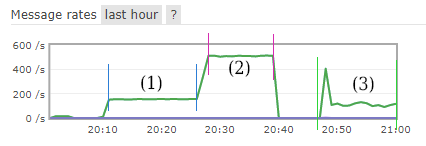
pool_mode=session, default_pool_size=2000, max_client_conn=2000, если я всё правильно понял из источников. Убрал пул из SQLAlchemy, соединил её с pgbounce и вроде всё работает, но не совсем так, как ожидалось. Тестировал различные конфигурации воркеров и вот что получилось. Ниже будет график из Rabbitmq по обработке сообщений в очереди. И я сейчас не понимаю, где искать затуп, который случился.LM
D
pool_mode=session, default_pool_size=2000, max_client_conn=2000, если я всё правильно понял из источников. Убрал пул из SQLAlchemy, соединил её с pgbounce и вроде всё работает, но не совсем так, как ожидалось. Тестировал различные конфигурации воркеров и вот что получилось. Ниже будет график из Rabbitmq по обработке сообщений в очереди. И я сейчас не понимаю, где искать затуп, который случился.D
S