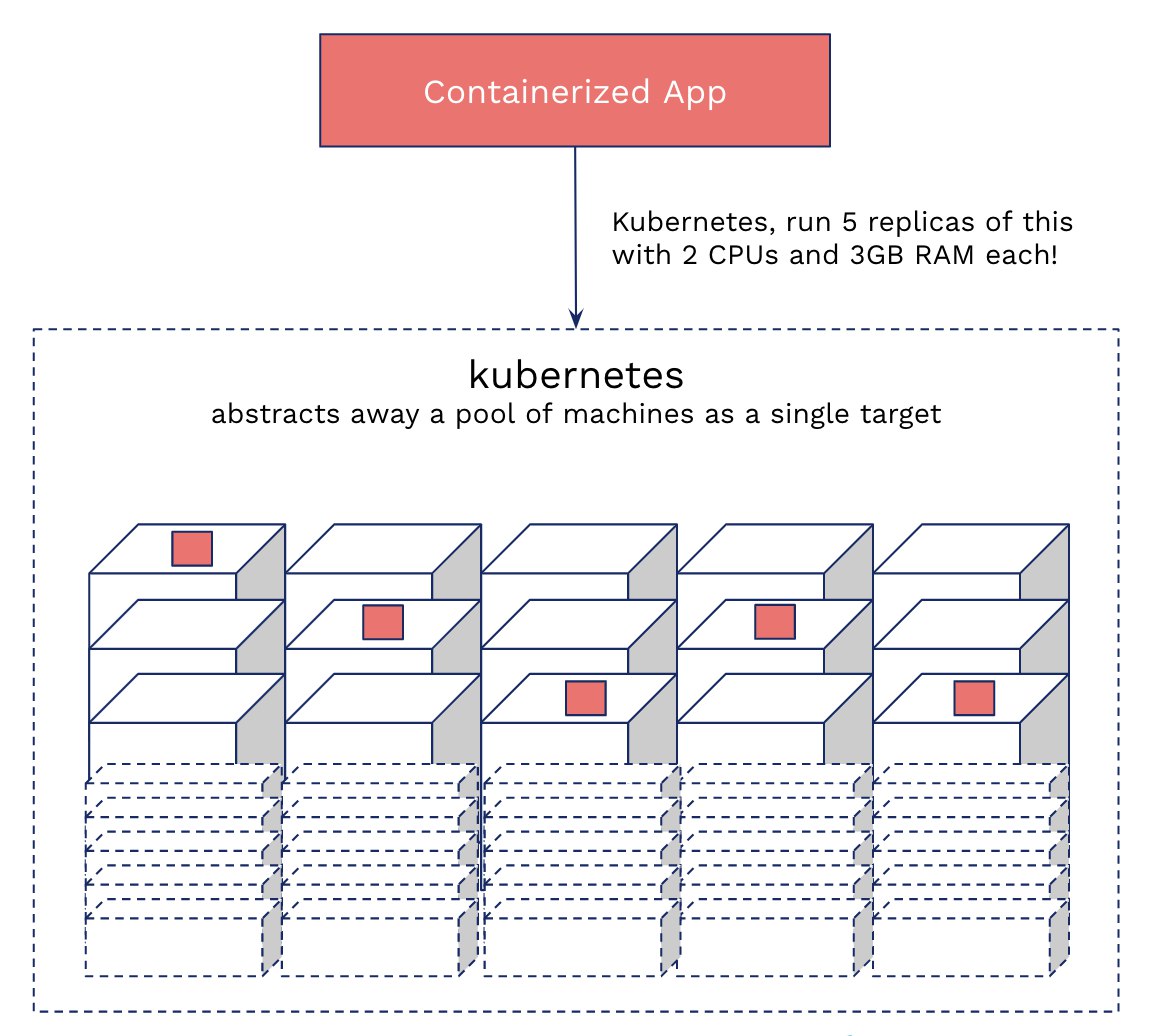
LB
С лимитами ответы могут рандомно на любом сервисе затупить до секунды, без лимитов такие проблемы пропали
точно уверены что в лимиты не упираетесь? посмотрите nr_throttled в cgroup
Size: a a a
LB
НК
НК
NG
ВЕ
КН
AM
LB
LB
AR
AR
ТФ
LB
IA
M
LB
command: ["/bin/sleep", "1", "kill -QUIT 1"]
G
ab утилите?ab -n N -c M http://example.orgab не подходит, потому что она не поддерживает HTTP 1.1LB
AR
M