e
пейтон и пейтон
да уж )) опять выбор из двух зол )
--
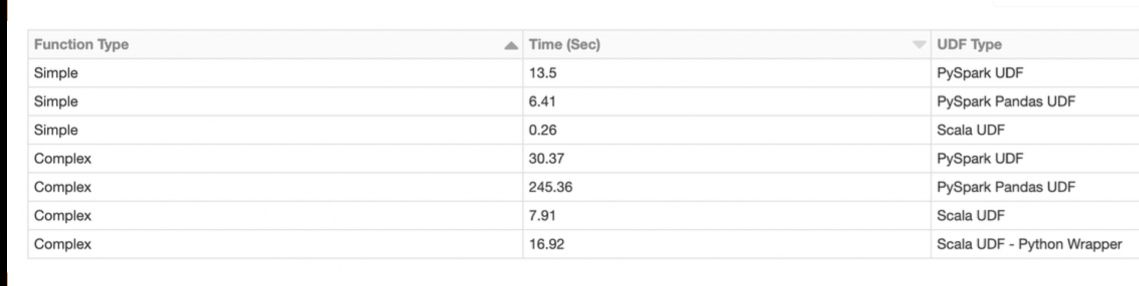
Пока PySpark действует в рамках стандартного API, по скорости он действительно может быть сравним со Scala.
При появлении специфичной логики в виде User Defined Functions производительность PySpark заметно снижается. При достаточном объеме информации, когда время обработки блока данных превышает несколько секунд, Python-реализация работает в 5-10 медленнее из-за необходимости перемещать данные между процессами и тратить ресурсы на интерпретацию Python.
Если же появляется использование дополнительных функций, реализованных в C++ модулях, то возникают дополнительные расходы на вызов, и разница между Python и Scala увеличивается до 10-50 раз.
--
https://habr.com/ru/company/odnoklassniki/blog/443324/
--
Пока PySpark действует в рамках стандартного API, по скорости он действительно может быть сравним со Scala.
При появлении специфичной логики в виде User Defined Functions производительность PySpark заметно снижается. При достаточном объеме информации, когда время обработки блока данных превышает несколько секунд, Python-реализация работает в 5-10 медленнее из-за необходимости перемещать данные между процессами и тратить ресурсы на интерпретацию Python.
Если же появляется использование дополнительных функций, реализованных в C++ модулях, то возникают дополнительные расходы на вызов, и разница между Python и Scala увеличивается до 10-50 раз.
--
https://habr.com/ru/company/odnoklassniki/blog/443324/