про локальные диски там было в контексте оптимизаций
что для шафла лучше использовать их, так как даёт более адекватную прозводительность
но в клауде зачастую подключаются remote, скорость которых пропорциональна размеру
поэтому или используйте локальные
или уже побольше размер для ремоут дисков запрашивайте
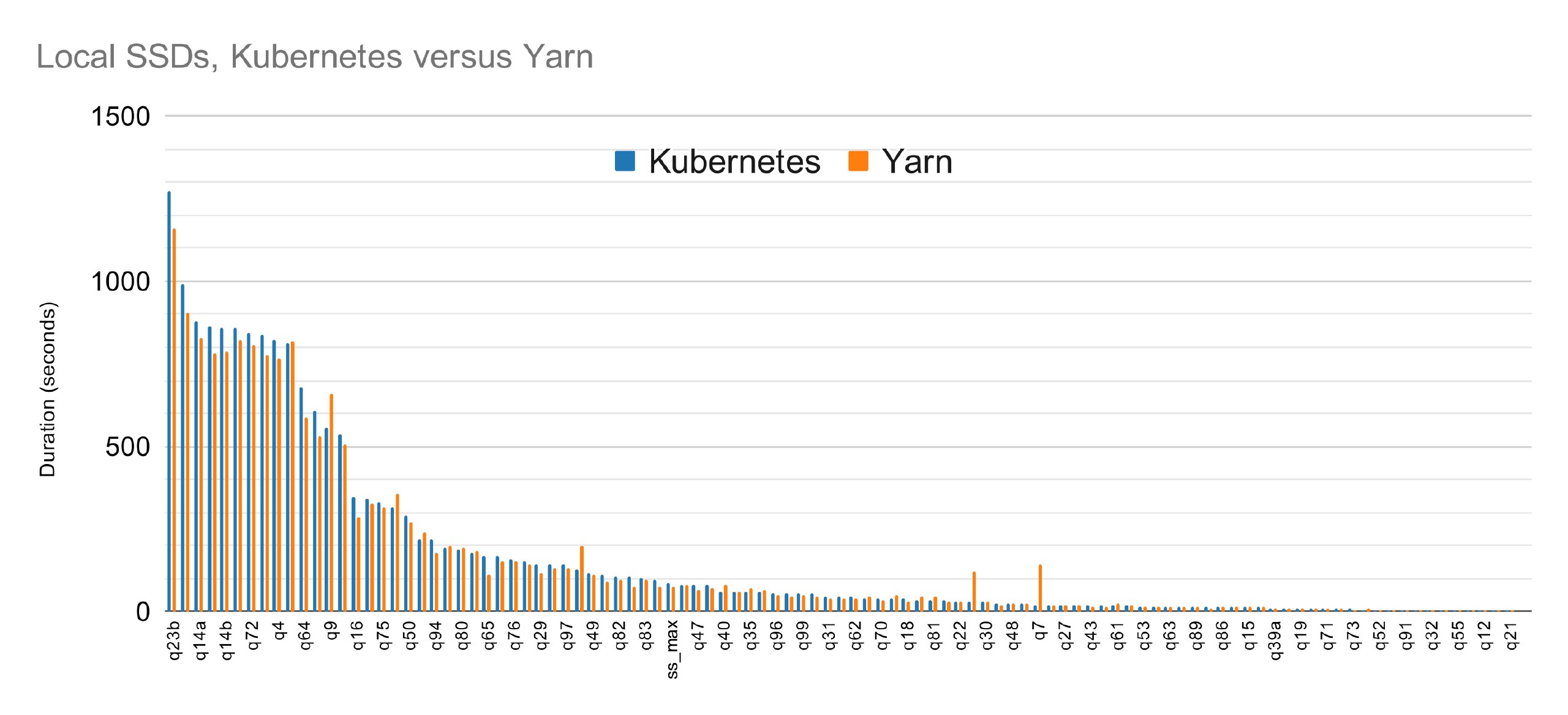
As we've shown, local SSDs perform the best, but here's a little configuration gotcha when running Spark on Kubernetes.
Simply defining and attaching a local disk to your Kubernetes is not enough: they will be mounted, but by default Spark will not use them. On Kubernetes, a hostPath is required to allow Spark to use a mounted disk.
то есть в случае кубика доп манипуляции с необходимы
без этого ещё больше разница будет чем 5%