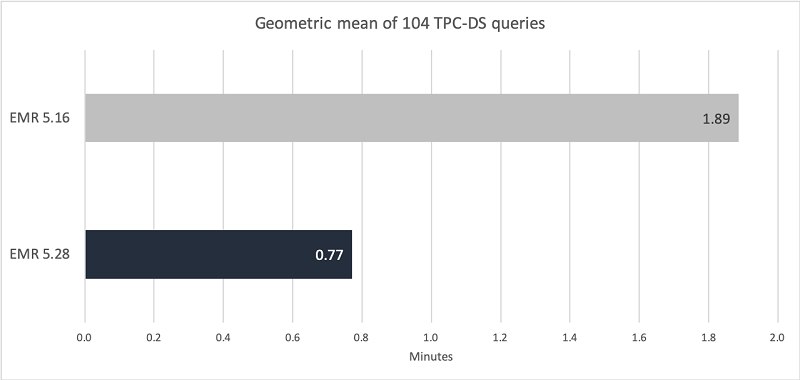
проведите бенчмарк. сделайте какой-нибудь расчёт, который много читает и много пишет, и убедитесь что времени на общение с с3 тратится во много раз больше, чем на сам расчёт
вот это правильно, мы в свое время проводили такое на своей нагрузке (обычные орк файлы, запись не интенсивная, обработка батчевая) размеры десятки терабайт, s3 проигрывал процентов 20% макс, а по стоимости разница была космическая