Привет всем, можете посоветовать статьи или что-то где можно было бы разобраться s3 и спарком, как они взаимодействуют, как Hadoop и с3... Как идёт вычитка и запись в файл
если кратко: копируйте в HDFS на кластере, будет сильно быстрее. до десятков раз в зависимости от условий
если кратко: копируйте в HDFS на кластере, будет сильно быстрее. до десятков раз в зависимости от условий
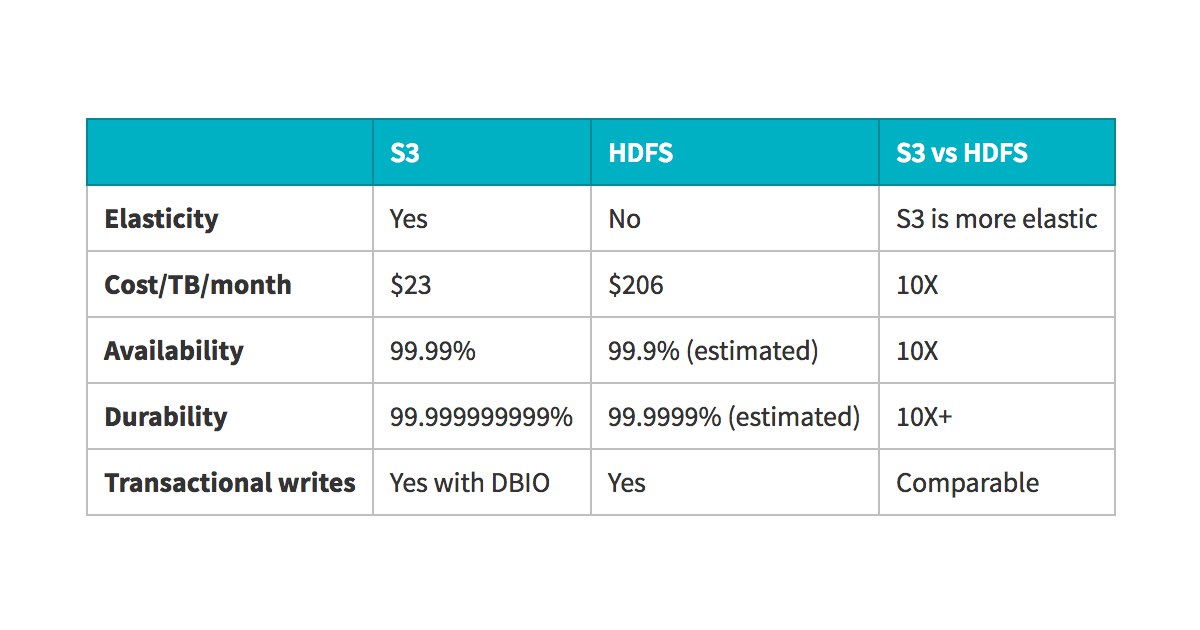
Тут возник вопрос в том что копирование на шдфс не хотят а сразу на с3... Но так как я не сильно в этом. Хочу разобраться в этом вопросе. Как быстрее, в чем плюсы и минусы
Тут возник вопрос в том что копирование на шдфс не хотят а сразу на с3... Но так как я не сильно в этом. Хочу разобраться в этом вопросе. Как быстрее, в чем плюсы и минусы
Тут возник вопрос в том что копирование на шдфс не хотят а сразу на с3... Но так как я не сильно в этом. Хочу разобраться в этом вопросе. Как быстрее, в чем плюсы и минусы
проведите бенчмарк. сделайте какой-нибудь расчёт, который много читает и много пишет, и убедитесь что времени на общение с с3 тратится во много раз больше, чем на сам расчёт
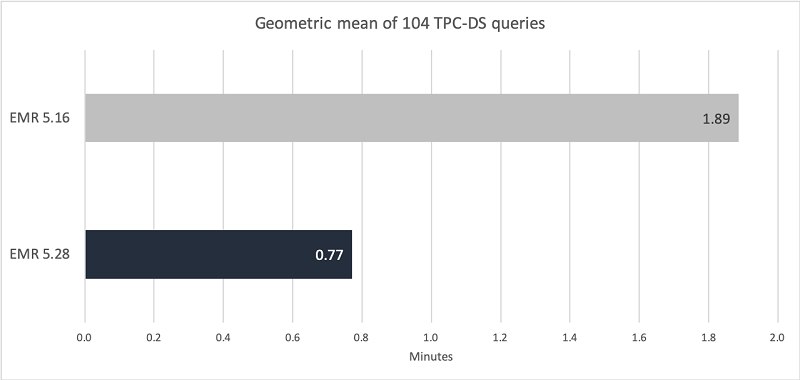
ну-ну, We used TPC-DS benchmark queries with 3 TB scale and ran them on a six-node c4.8xlarge EMR cluster там какой линк до с3 с таким размером ноды? 10гбит?