AZ
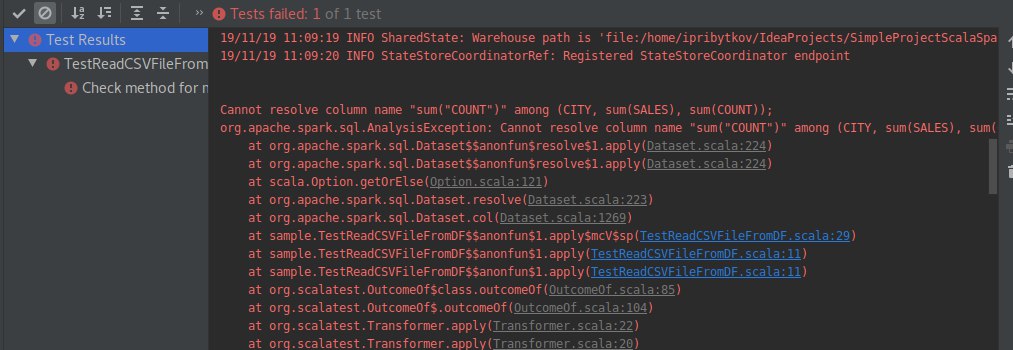
А поясните плиз нубу про проблему скейлинга в кафка стримс и чем flink/spark приятнее в этом вопросе
kstreams это библиотека, там нет сервера приложений / кластера как такогового, авторам нужно самим решать сколько воркеров и где запустить, решать проблему их переподьема и расширения