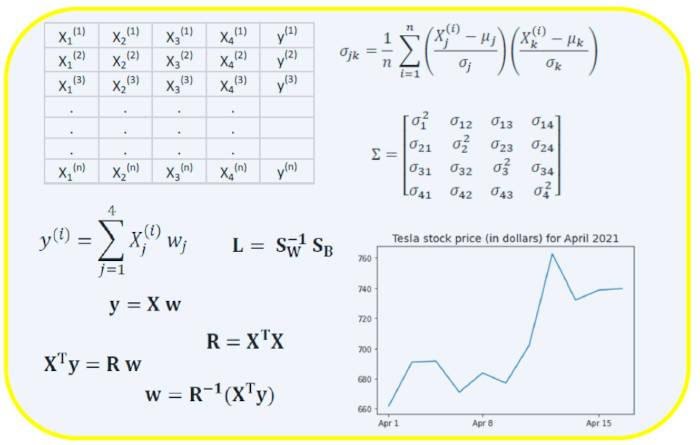
Сбер приглашает на свою первую масштабную технологическую конференцию - SmartDev. Сбер представит свои новые возможности для разработчиков, презентует новые условия и возможности сервиса SberCloud.Advanced.
⏱ 20 мая
👨💻 Онлайн и бесплатно
🎯 Регистрация
Шесть параллельных стримов от шести технологических стеков Сбера. 50+ спикеров, которые поделятся опытом и представят новые решения для разработчиков, аналитиков и специалистов по Data Science.
Один из стримов будет посвящен облачной платформе от Сбера - SberCloud. Команда представит новые возможности SberCloud.Advanced — самой широкой линейки платформенных сервисов в России. Теперь все они доступны для физических лиц, через быстрый и удобный self-service.
Вы узнаете, как создавать различные компоненты приложения с помощью всех необходимых платформ облака. Поговорим про работу Apache Spark c Big Data в кластере SberCloud и про создание инфраструктуры с помощью Terraform по принципу Infrastructure-as-Code.
Зарегистрируйтесь, чтобы принять участие.
⏱ 20 мая
👨💻 Онлайн и бесплатно
🎯 Регистрация
Шесть параллельных стримов от шести технологических стеков Сбера. 50+ спикеров, которые поделятся опытом и представят новые решения для разработчиков, аналитиков и специалистов по Data Science.
Один из стримов будет посвящен облачной платформе от Сбера - SberCloud. Команда представит новые возможности SberCloud.Advanced — самой широкой линейки платформенных сервисов в России. Теперь все они доступны для физических лиц, через быстрый и удобный self-service.
Вы узнаете, как создавать различные компоненты приложения с помощью всех необходимых платформ облака. Поговорим про работу Apache Spark c Big Data в кластере SberCloud и про создание инфраструктуры с помощью Terraform по принципу Infrastructure-as-Code.
Зарегистрируйтесь, чтобы принять участие.