



Выходные (кластерные) элементы сети Кохонена обычно представляют расположенными тем или иным образом в двумерном пространстве.
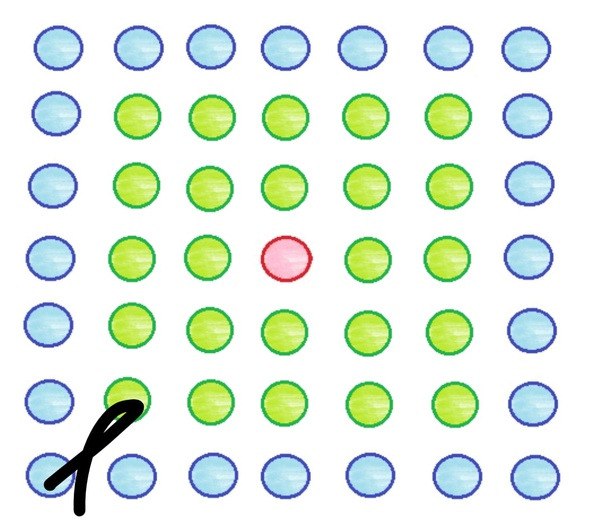
Выходные (кластерные) элементы сети Кохонена обычно представляют расположенными тем или иным образом в двумерном пространстве. Разместим, к примеру, выходные элементы в виде квадратной сетки и зададим начальный радиус обучения равным 2. Подаем на вход сети вектор и элементом-победителем оказывается нейрон, обозначенный на схеме красным цветом. По алгоритму обучения мы должны обновить значения весов для этого нейрона, а также для тех, которые попадают в круг заданного радиуса (в данном случае 2) – эти элементы выделены зеленым: (1)
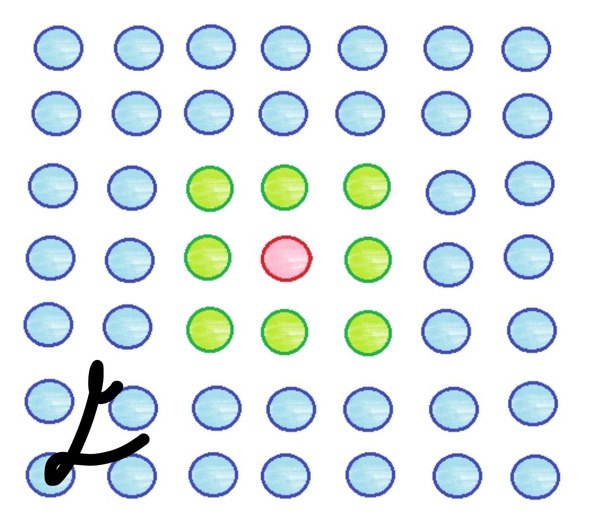
Ближе к концу процесса обучения радиус уменьшается. Пусть он стал равным единице, тогда обновляться будут веса следующих элементов: (2)
Итак, разобрав все составляющие процесса обучение давайте напишем конкретный алгоритм для этого процесса:
берем учебный вектор и вычисляем квадрат евклидова расстояния от него до каждого из кластерных элементов сети
находим минимальное из полученных значений и определяем элемент-победитель
для нейрона-победителя, а также для тех нейронов, которые попали в заданный радиус, выполняем корректировку весов связей
обновляем значения нормы обучения и радиуса
продолжаем обучение, если не выполнено условие остановки обучения
Остановка обучения происходит в том случае, если величины изменения весов становятся очень маленькими. И на этом моменте предлагаю сегодня остановиться, поскольку статья получилась довольно большой.












