



BZ
Size: a a a
2021 January 15

d
MM
Что ж это такое сегодня ((
RS
Надо защиту от ботов ставить)
d
Что ж это такое сегодня ((
Есть @protectronbot, если что. Популярен, много умеет. И в ML умеет
MM
Есть @protectronbot, если что. Популярен, много умеет. И в ML умеет
Спасибо. В понедельник изучу
ВА
На телефоне тоже курсера у меня не работает. Кто-нибудь может знать, почему?
SK
попробуйте через какую нибудь открытую проксю
ВА
через VPN получилось войти. В интернете пишут, что возможно это из-за того, что меня заблокировали на сайте
d
через VPN получилось войти. В интернете пишут, что возможно это из-за того, что меня заблокировали на сайте
Предположу, что это происходит, потому что, Coursera использует CloudFare, а некоторые его адреса забанены Роскомнадзором.
ВА
я тоже так подумал. Но как бороться с этим, пока не придумал
d
я тоже так подумал. Но как бороться с этим, пока не придумал
Opera + ее встроенный VPN
ВА
помогло, спасибо!
АМ
Немного не по теме ML, но все же
Если я завершу курс с рейтингом, например, 90% и получу соответствующий сертификат - будет ли у меня возможность позже "пересдать" его на 100% или это фиксируется по завершении сессии навсегда?
Если я завершу курс с рейтингом, например, 90% и получу соответствующий сертификат - будет ли у меня возможность позже "пересдать" его на 100% или это фиксируется по завершении сессии навсегда?
2021 January 16
SM
Ребят, есть задача написать детектор частей изображения (генерирует bounding boxes), который по некоторому алгоритму (или с помощью нейросети [не знаю, как лучше]) преобразует задетекченные bounding boxes и добавляет к исходному изображению.
При этом это должно работать в финале на Android/iOS. Какими языками и библиотеками пользоваться? Какие методы применить для 1 и второй части
При этом это должно работать в финале на Android/iOS. Какими языками и библиотеками пользоваться? Какие методы применить для 1 и второй части
МЛ
Александр Мелехин
Немного не по теме ML, но все же
Если я завершу курс с рейтингом, например, 90% и получу соответствующий сертификат - будет ли у меня возможность позже "пересдать" его на 100% или это фиксируется по завершении сессии навсегда?
Если я завершу курс с рейтингом, например, 90% и получу соответствующий сертификат - будет ли у меня возможность позже "пересдать" его на 100% или это фиксируется по завершении сессии навсегда?
на бумажке сертификата оценка не пишется, только на соотв.странице где она может обновляться (вроде как)
IM
Ребят, есть задача написать детектор частей изображения (генерирует bounding boxes), который по некоторому алгоритму (или с помощью нейросети [не знаю, как лучше]) преобразует задетекченные bounding boxes и добавляет к исходному изображению.
При этом это должно работать в финале на Android/iOS. Какими языками и библиотеками пользоваться? Какие методы применить для 1 и второй части
При этом это должно работать в финале на Android/iOS. Какими языками и библиотеками пользоваться? Какие методы применить для 1 и второй части
Зависит от того что тебе надо детектить, есть объекты которые умеет находить opencv из коробки, им же можно нанести bounding box на изображение и вывести куда тебе нужно, тогда всё относительно просто, можешь брать c++ и open cv. Либо использовать реализации под kotlin и swift (библиотека адаптирована под многие языки) . Если у тебя объекты весьма специфичны (под которые ты не смог найти что-то готовое). То скорее всего путь лежит через сетки (torch) либо любой другой алгоритм (SIFT Matching) , где ты выбираешь пилить c++ с допилами под обе платформы. Или пилишь разные реализации на kotlin/Java и swift.
АБ
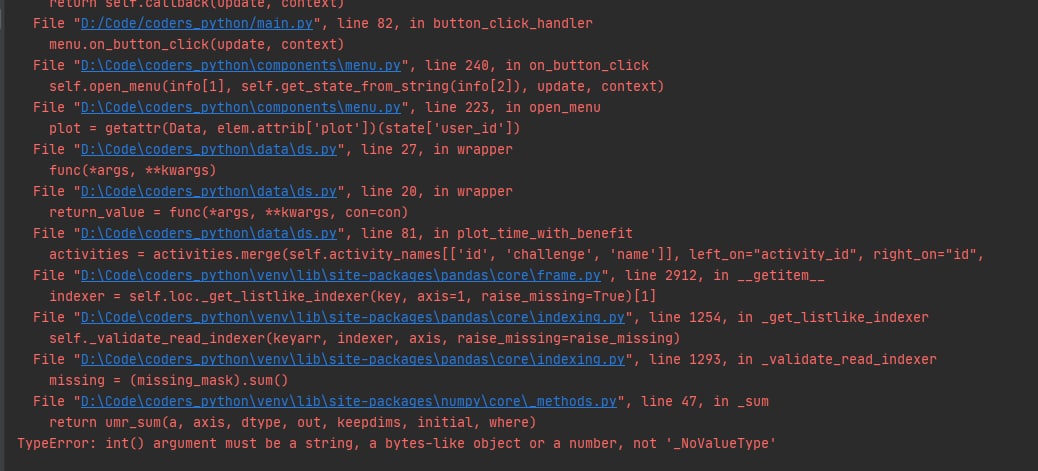
Всем привет. Есть такая проблема: один и тот же код одним и тем же интерпретатором нормально работает при запуске через консоль командой
Проблема возникает при выполнении pd.read_sql_query. Когда я хочу использовать где-то результат выполнения функции, возникает ошибка, которая на скрине. При запуске через консоль все отлично работает.
Кто-то сталкивался с подобной проблемой?
.\venv\Scripts\python.exe main.py, но при этом не работает нормально при запуске через Pycharm. Проблема возникает при выполнении pd.read_sql_query. Когда я хочу использовать где-то результат выполнения функции, возникает ошибка, которая на скрине. При запуске через консоль все отлично работает.
Кто-то сталкивался с подобной проблемой?
AO
подскажите. есть тензор(c/w/h) - 64/128/128. я хочу поэлементно умножить его на матрицу 128/128 нулей и единиц (маска).
я могу застекать и сделать 64 канала идентичных матриц и потом перемножить эти два тенхора. Но в памяти будет 64 идентичных картинки. это дорого. как проще мне перемножить тензор 64/128/128 на 1/128/128?
я могу застекать и сделать 64 канала идентичных матриц и потом перемножить эти два тенхора. Но в памяти будет 64 идентичных картинки. это дорого. как проще мне перемножить тензор 64/128/128 на 1/128/128?