



GM
Size: a a a
2020 June 04

GM
кто-то сталкивался с такой проблемой
GM
в C2W3?
И
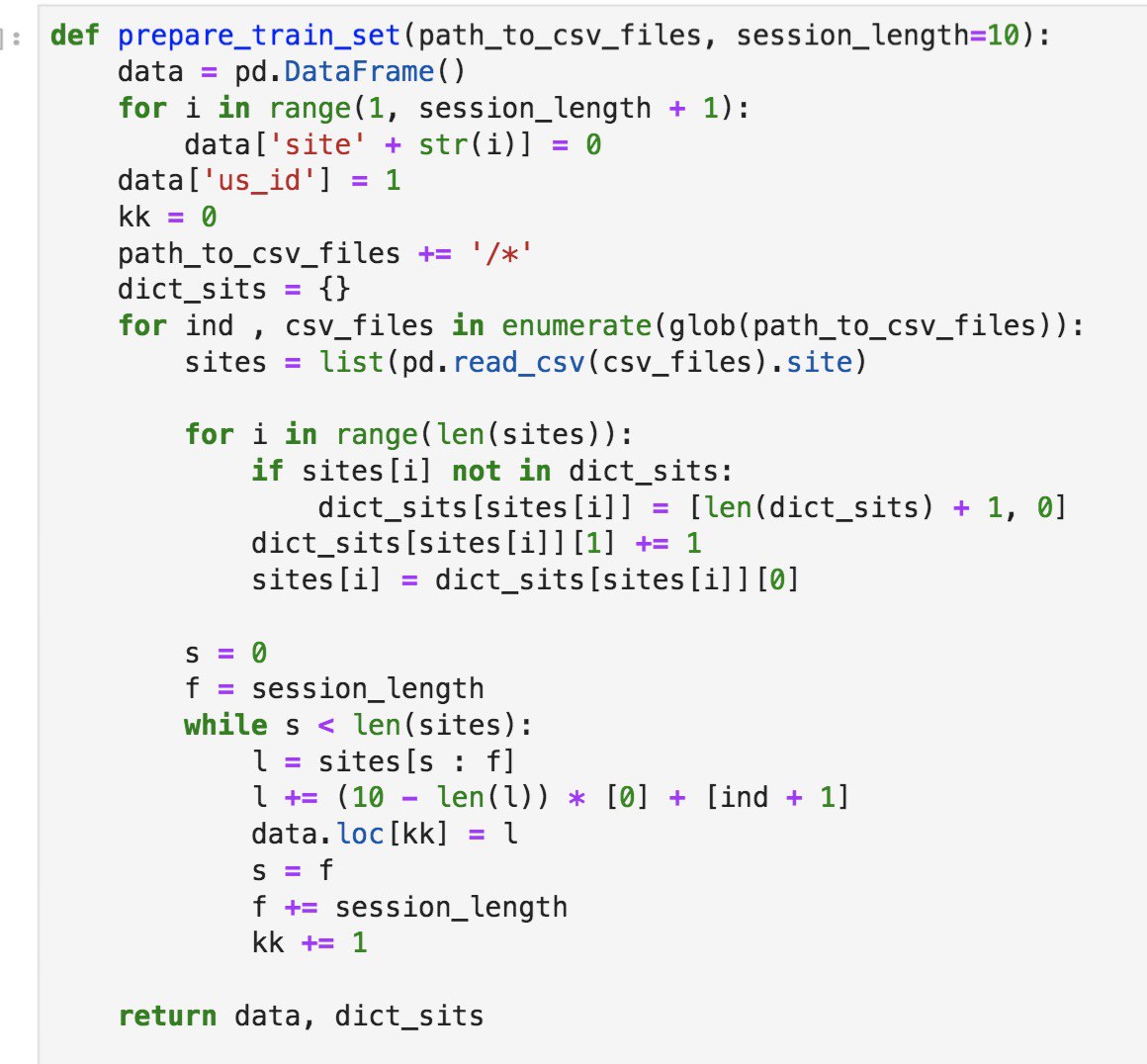
c6w1
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
N
Text Mining in Python: Steps and Examples
This blog summarizes text preprocessing and covers the NLTK steps including Tokenization, Stemming, Lemmatization, POS tagging, Named entity recognition and Chunking.
https://www.kdnuggets.com/2020/05/text-mining-python-steps-examples.html
This blog summarizes text preprocessing and covers the NLTK steps including Tokenization, Stemming, Lemmatization, POS tagging, Named entity recognition and Chunking.
https://www.kdnuggets.com/2020/05/text-mining-python-steps-examples.html

2020 June 05
АГ
в C2W3?
Судя по всему, вы передаёте массив длиной 1, при этом подразумевается индекс 6000. Проверьте вручную передаваемые данные, их размерность
АК
C6W3 Отток, проверьте работу пожалуйста
https://www.coursera.org/learn/data-analysis-project/peer/am9Gl/postroieniie-baseline-rieshienii/review/oAOHzKbHEeqVyApnk24R4w
https://www.coursera.org/learn/data-analysis-project/peer/am9Gl/postroieniie-baseline-rieshienii/review/oAOHzKbHEeqVyApnk24R4w

АГ
c6w1
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
А может разделить построение словаря и Запись сессий? Построить словарь, отсортировать его, а потом уже снова по пользователям пройтись, записывая id из словаря в предварительно подготовленные нп зирос для сессий, затем их в df преобразовать..
АГ
c6w1
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
Все же, думаю, сортировка облегчит затем сверку, при этом нампай обработать может оказаться несколько быстрее множества обращений к df сделать... А так алгоритм по сложности примерно такой же получается, просто операции побыстрее могут получиться, в скорости может быть прибавка.
АГ
c6w1
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
ребят, весь день пытаюсь оптимизировать код, но пока дело не идет, кто-то может дать совет, что нужно делать?
Ещё у меня есть сомнение, что ваш код обрабатывает неполные сессии, поскольку если длина запрашиваемого среза больше того, что осталось, то может выдаваться пустой массив для таких сессий..
RY
Переслано от Ruslan515 Y

Кострикин. Задача 26.1. д) почему такой ответ? у меня получилось x^4+x^3+x^2+x+1. остаток 1
RY

AR
На собеседовании задали вопрос: "Данные стоят денег. Как ты будешь оценивать количество данных, которые можно обработать за такое количество денег?" Ответил, что зависит от модели, данных и задачи. К примеру, нейронкам надо много данных для обработки изображений, а для бинарной классификации векторов хватит небольшого количества данных и SVM. Если данные плохие (много null и пропусков), то качество не добьёшься.
Как бы вы на это ответили на этот вопрос?
Как бы вы на это ответили на этот вопрос?
АК
На собеседовании задали вопрос: "Данные стоят денег. Как ты будешь оценивать количество данных, которые можно обработать за такое количество денег?" Ответил, что зависит от модели, данных и задачи. К примеру, нейронкам надо много данных для обработки изображений, а для бинарной классификации векторов хватит небольшого количества данных и SVM. Если данные плохие (много null и пропусков), то качество не добьёшься.
Как бы вы на это ответили на этот вопрос?
Как бы вы на это ответили на этот вопрос?
Я бы примерно так же и ответил. Возможно, я бы добавил, что в ряде случаев (нормальное распределение и определенный доверительный интервал) можно примерно определить размер выборки, чтобы она была репрезентативной. Зная, сколько стоит условно одна запись, можно сказать, будет ли достаточно выделенного бюджета для формирования нужной выборки.
P
Переслано от Ruslan515 Y
Кострикин. Задача 26.1. д) почему такой ответ? у меня получилось x^4+x^3+x^2+x+1. остаток 1
в ответе просто представлена форма, из которой очень просто сделать новую функцию, аргументом которой и будет х-х0, а так ответы правильные. Непонятно только, зачем так сделано, проще просто разделить
АК
На собеседовании задали вопрос: "Данные стоят денег. Как ты будешь оценивать количество данных, которые можно обработать за такое количество денег?" Ответил, что зависит от модели, данных и задачи. К примеру, нейронкам надо много данных для обработки изображений, а для бинарной классификации векторов хватит небольшого количества данных и SVM. Если данные плохие (много null и пропусков), то качество не добьёшься.
Как бы вы на это ответили на этот вопрос?
Как бы вы на это ответили на этот вопрос?
Также возникает вопрос о том, как эти изображения были собраны, есть ли разрешение на их использование. Мне кажется, что в ряде случаев можно значительно снизить стоимость исходных данных, если предоставить бесплатный сервис, который выдает какой-то побочный продукт обработки этих данных на условиях предоставления разрешения на их использование. Типа сделать сервис, который накладывает фильтр на фото, которое присылает пользователь, и в условиях пользования прописать, что эти изображения могут быть использованы для разработки внутренних продуктов.
Тогда можно посчитать, сколько будет стоить разработка и продвижение такого приложения, и если это будет дешевле, чем закупать эти данные, то лучше поднять такой сервис,
Тогда можно посчитать, сколько будет стоить разработка и продвижение такого приложения, и если это будет дешевле, чем закупать эти данные, то лучше поднять такой сервис,
AR
Это был общий вопрос. По изображения я просто привёл пример. Можно пойти дальше: добавить изображениям шум, отзеркалить, слегка перевернуть и т.п.
АК
На собеседовании задали вопрос: "Данные стоят денег. Как ты будешь оценивать количество данных, которые можно обработать за такое количество денег?" Ответил, что зависит от модели, данных и задачи. К примеру, нейронкам надо много данных для обработки изображений, а для бинарной классификации векторов хватит небольшого количества данных и SVM. Если данные плохие (много null и пропусков), то качество не добьёшься.
Как бы вы на это ответили на этот вопрос?
Как бы вы на это ответили на этот вопрос?
Еще данные требуют денег на хранение, а это периодический постоянный (или постоянно растущий) расход. Нужно учитывать, может ли компания данные хранить и обрабатывать.
АК
Это был общий вопрос. По изображения я просто привёл пример. Можно пойти дальше: добавить изображениям шум, отзеркалить, слегка перевернуть и т.п.
Я понимаю. Просто не имея данных о самой компании и интервьюере приходится из пальца высасывать и придумывать на ходу)
АК
Это был общий вопрос. По изображения я просто привёл пример. Можно пойти дальше: добавить изображениям шум, отзеркалить, слегка перевернуть и т.п.
А Вы уже закончили специализацию?