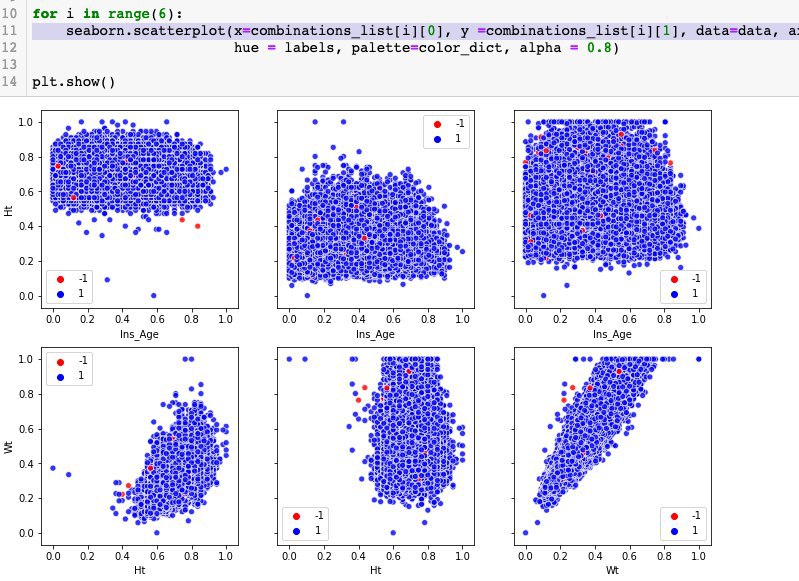
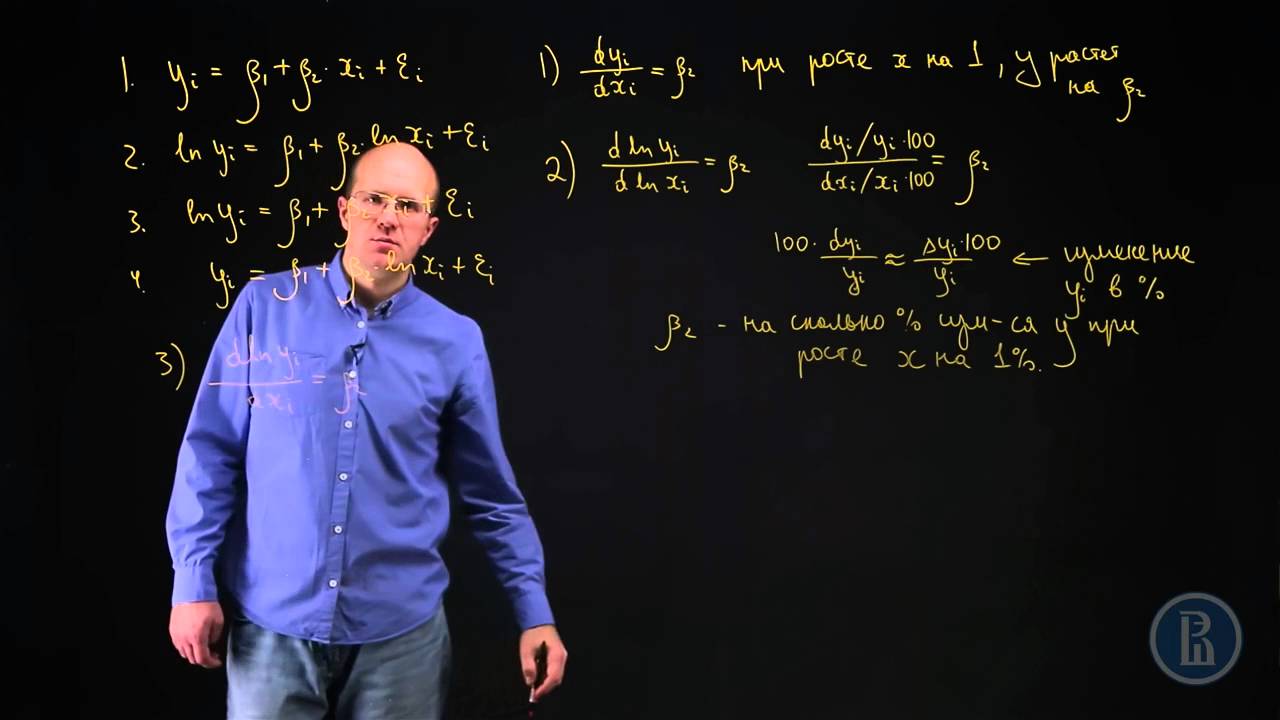Здесь нужен массив нулей np. zeros(), а предложения превратить в массивы с помощью split(). Количество вхождений слова в массив count(). Также понадобится словарь dict, куда слова будут записываться в ключи для удобства поиска потом. Вроде d это размерность этого словаря, а точнее массива уникальных ключей словаря .keys() . Весь процесс представляет собой превращение предложений в векторы(строки с частотами) , чтобы находить расстояния между ними.
а зачем создавать нулевой массив? разве нельзя создать пустой а затем в него добавлять?
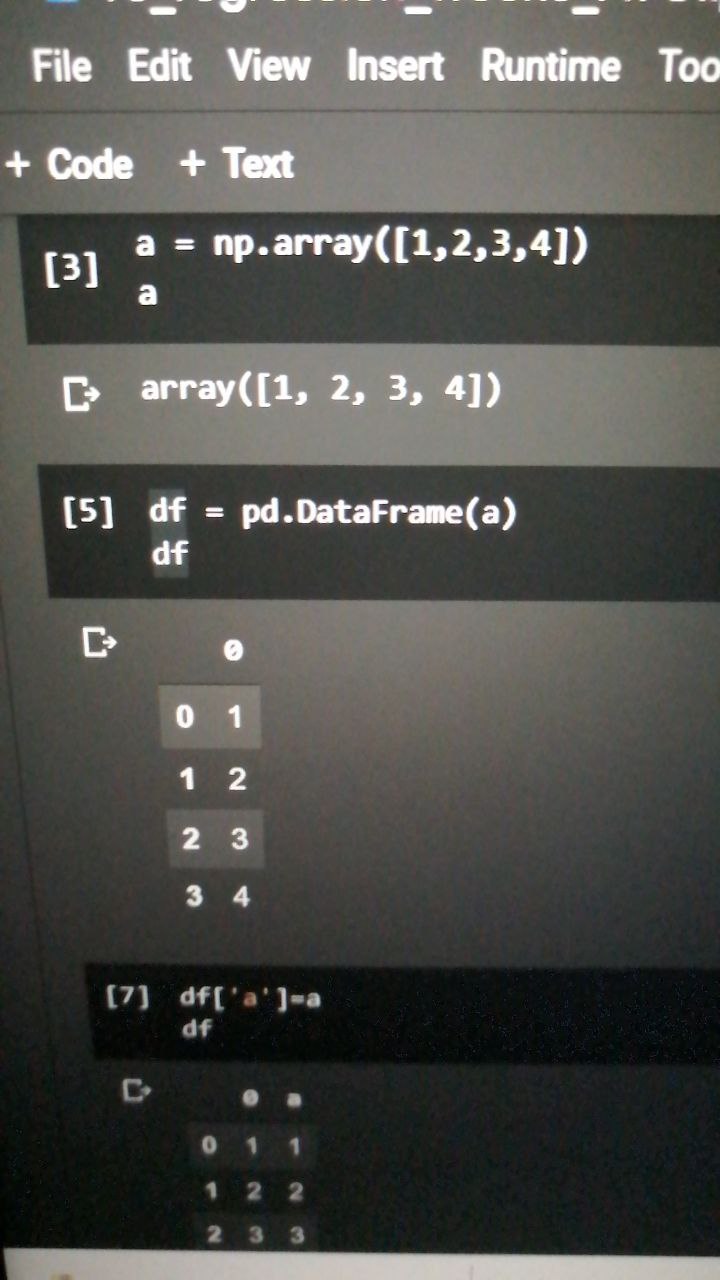
Кстати, вопрос по поводу массивов от numpy: как их можно вставить в DataFrame? Массив numpy представляет собой array[[0,0,0]], а DataFrame принимает только [0,0,0].
Кстати, вопрос по поводу массивов от numpy: как их можно вставить в DataFrame? Массив numpy представляет собой array[[0,0,0]], а DataFrame принимает только [0,0,0].
подскажите. часто используют логарифимирование зависимой переменой . например в задачах регрессиии. Я правильно понимаю - что это делается в целях сделать модель более линейной для того что бы mse лучше работало? и если да, то данная операция бесполезна если я буду использовать деревья и бустинг над ними - он ок и не с линейными моделямя работают? я прав?
Какие есть альтернативы современные. У меня пару сотен диалогов, нужно разбить их на 10, 15, 20 тем
Что-то сразу в голову не пришло. Если выборка с текстами не размечена, то кроме bigartm, можно использовать TfidfVectorizer с любым методом кластеризации данных. И визуализировать с помощью t-sne, чтобы понять, хорошо ли кластеризовалось