



K
Size: a a a
2020 August 26
SS
300кк/наносек же :)
Это отсылка на одного известного товарища из х5 и его собесы с хуавей
П
Это отсылка на одного известного товарища из х5 и его собесы с хуавей
Видимо, не проникся духом компании... Бывает
SS
Павел
Видимо, не проникся духом компании... Бывает
Скорее сыграла разность менталитетов.
N
ВСем привет! читаю учебник по машинному обучению и столкнулся с небольшим непониманием
N

Автор пишет
- Увеличение числа соседей приводит к сглаживанию границы принятия решений - То есть чем больше соседей тем более гладкая граница
- Более гладкая граница соответствует более простой модели - чем граница "глаже" тем модель проще. То есть чем больше соседей тем проще модель.
- использование нескольких соседей соответствует высокой сложности модели, а использование большого количества соседей соответствует низкой сложности модели - вот тут то и путаница.
то ли я тупой то ли в книге ошибка/опечатка
- Увеличение числа соседей приводит к сглаживанию границы принятия решений - То есть чем больше соседей тем более гладкая граница
- Более гладкая граница соответствует более простой модели - чем граница "глаже" тем модель проще. То есть чем больше соседей тем проще модель.
- использование нескольких соседей соответствует высокой сложности модели, а использование большого количества соседей соответствует низкой сложности модели - вот тут то и путаница.
то ли я тупой то ли в книге ошибка/опечатка
N
увеличение числа соседей усложняет модель и сглаживает границу или упрощает ее?
N
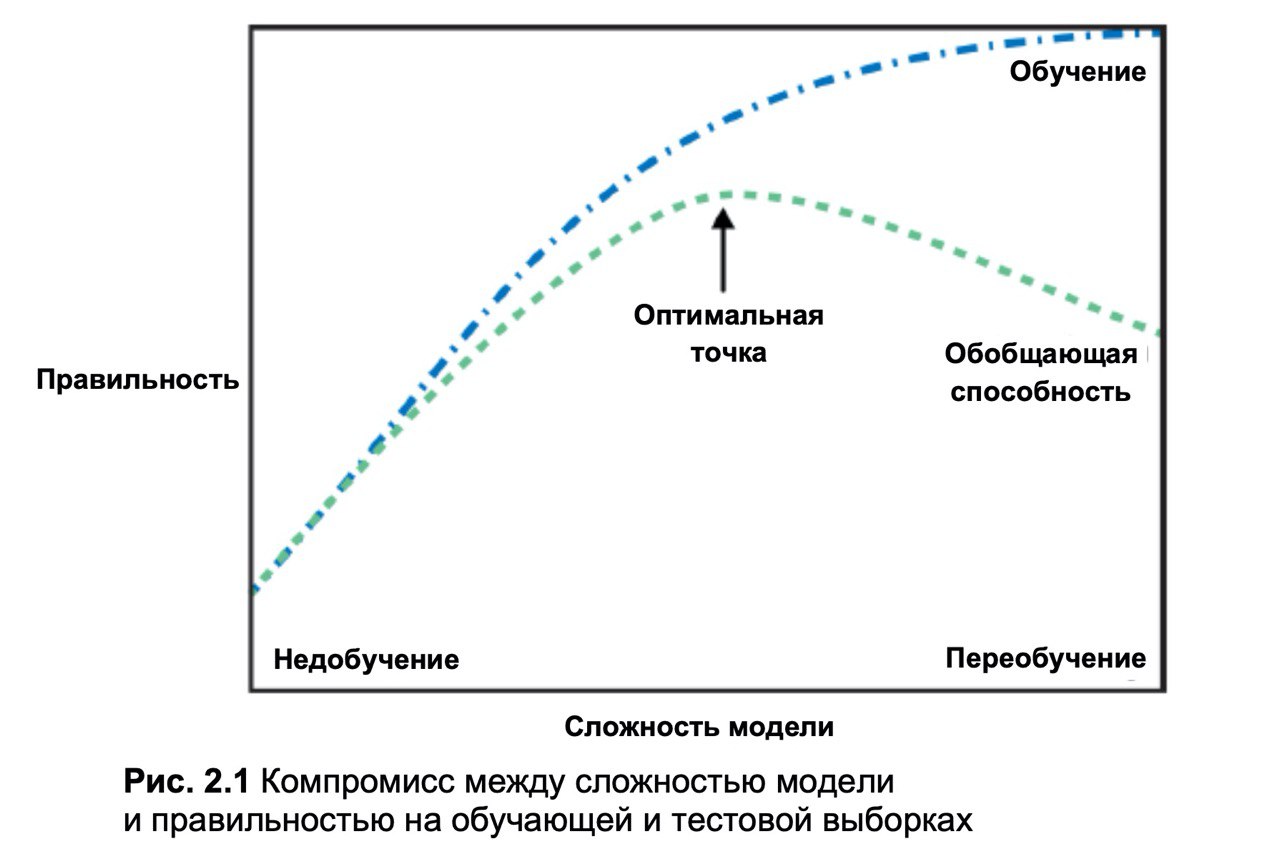
насчет того что сказано что это рисунок 2.1 мне кажется что это опечатка ибо он в совершенно другой главе и там изображено совсем другое
DD
увеличение числа соседей усложняет модель и сглаживает границу или упрощает ее?
Понятие "сложности модели" в основном используется в контексте параметрических моделей - таких, обучение которых сводится к подгону параметров под данные. Это, например, линейные модели и нейронки, где выучиваются коэффициенты, или древесные модели, где выучиваются бинарные решающие правила (по какому признаку и по какому его значению нынче разветвиться).
И в таких моделях чем больше параметров, тем больше у модели возможностей подогнаться под данные, а значит, тем более сложную границу модель может выучить, но и тем больше возможность оверфитнуться. В этом смысле, чем больше параметров, тем сложнее модель, тем больше обучения и переобучения.
А метод ближайших соседей - это непараметрическая модель, в том смысле, что её обучение не сводится к изменению параметров. Вообще, у knn обучаемых параметров вообще нет, а есть только гиперпараметры - число соседей и метрика расстояния. Соответственно, связка "число параметров - сложность модели" для knn вообще не применима.
И в таких моделях чем больше параметров, тем больше у модели возможностей подогнаться под данные, а значит, тем более сложную границу модель может выучить, но и тем больше возможность оверфитнуться. В этом смысле, чем больше параметров, тем сложнее модель, тем больше обучения и переобучения.
А метод ближайших соседей - это непараметрическая модель, в том смысле, что её обучение не сводится к изменению параметров. Вообще, у knn обучаемых параметров вообще нет, а есть только гиперпараметры - число соседей и метрика расстояния. Соответственно, связка "число параметров - сложность модели" для knn вообще не применима.
N
Понятие "сложности модели" в основном используется в контексте параметрических моделей - таких, обучение которых сводится к подгону параметров под данные. Это, например, линейные модели и нейронки, где выучиваются коэффициенты, или древесные модели, где выучиваются бинарные решающие правила (по какому признаку и по какому его значению нынче разветвиться).
И в таких моделях чем больше параметров, тем больше у модели возможностей подогнаться под данные, а значит, тем более сложную границу модель может выучить, но и тем больше возможность оверфитнуться. В этом смысле, чем больше параметров, тем сложнее модель, тем больше обучения и переобучения.
А метод ближайших соседей - это непараметрическая модель, в том смысле, что её обучение не сводится к изменению параметров. Вообще, у knn обучаемых параметров вообще нет, а есть только гиперпараметры - число соседей и метрика расстояния. Соответственно, связка "число параметров - сложность модели" для knn вообще не применима.
И в таких моделях чем больше параметров, тем больше у модели возможностей подогнаться под данные, а значит, тем более сложную границу модель может выучить, но и тем больше возможность оверфитнуться. В этом смысле, чем больше параметров, тем сложнее модель, тем больше обучения и переобучения.
А метод ближайших соседей - это непараметрическая модель, в том смысле, что её обучение не сводится к изменению параметров. Вообще, у knn обучаемых параметров вообще нет, а есть только гиперпараметры - число соседей и метрика расстояния. Соответственно, связка "число параметров - сложность модели" для knn вообще не применима.
ну так если эта связка не применима зачем о ней написали в учебнике?
DD
Увеличение числа соседей совершенно точно сглаживает границу.
А называть это упрощением или усложнением - вопрос философский. Лично я бы сказал, что сложность модели не изменилось, т.к. число гиперпараметров осталось тем же, и в памяти модели хранятся всё те же точки.
А называть это упрощением или усложнением - вопрос философский. Лично я бы сказал, что сложность модели не изменилось, т.к. число гиперпараметров осталось тем же, и в памяти модели хранятся всё те же точки.
DD
ну так если эта связка не применима зачем о ней написали в учебнике?
С другой стороны, можно считать, что "сложность модели" = "сложность выучиваемой ею границы".
И тогда увеличение числа соседей => более простая граница => сложность модели меньше.
И в этом смысле автор написал всё правильно.
И тогда увеличение числа соседей => более простая граница => сложность модели меньше.
И в этом смысле автор написал всё правильно.
N
С другой стороны, можно считать, что "сложность модели" = "сложность выучиваемой ею границы".
И тогда увеличение числа соседей => более простая граница => сложность модели меньше.
И в этом смысле автор написал всё правильно.
И тогда увеличение числа соседей => более простая граница => сложность модели меньше.
И в этом смысле автор написал всё правильно.
ааа
N
С другой стороны, можно считать, что "сложность модели" = "сложность выучиваемой ею границы".
И тогда увеличение числа соседей => более простая граница => сложность модели меньше.
И в этом смысле автор написал всё правильно.
И тогда увеличение числа соседей => более простая граница => сложность модели меньше.
И в этом смысле автор написал всё правильно.
то есть чем проще рельеф границы тем проще сама модель?
DD
> использование нескольких соседей соответствует высокой сложности модели, а использование большого количества соседей соответствует низкой сложности модели - вот тут то и путаница.
Это суждение, которое тебе не понравилось - верное, если понимать сложность в том смысле, в котором я написал в предыдущем сообщении.
Это суждение, которое тебе не понравилось - верное, если понимать сложность в том смысле, в котором я написал в предыдущем сообщении.
DD
то есть чем проще рельеф границы тем проще сама модель?
Мне кажется, автор имел в виду именно это.
Но вообще я предлагаю отказаться от понятия "сложность", которое какое-то слишком философское, и использовать вместо этого что-то вроде "выразительной силы",
Но вообще я предлагаю отказаться от понятия "сложность", которое какое-то слишком философское, и использовать вместо этого что-то вроде "выразительной силы",
N
> использование нескольких соседей соответствует высокой сложности модели, а использование большого количества соседей соответствует низкой сложности модели - вот тут то и путаница.
Это суждение, которое тебе не понравилось - верное, если понимать сложность в том смысле, в котором я написал в предыдущем сообщении.
Это суждение, которое тебе не понравилось - верное, если понимать сложность в том смысле, в котором я написал в предыдущем сообщении.
спасибо! теперь понятно
DD
Чем больше разных заковыристых границ модель может выучить, тем более выразительной её можно считать.
N
Чем больше разных заковыристых границ модель может выучить, тем более выразительной её можно считать.
спасибо за помощь нубу)) при встрече с меня кружка))
DD
Чем больше разных заковыристых границ модель может выучить, тем более выразительной её можно считать.
В параметрических моделях эта выразительная сила обычно коррелирует с числом параметров. Но она зависит не только от них, например, с увеличением регуляризации выразительная сила уменьшается при неизвестном числе параметров. В этом смысле число соседей можно рассматривать как гиперпараметр, отвечающий за регуляризацию.