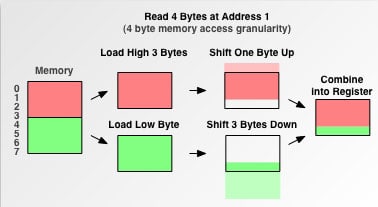
Давай по-новой.
byte - выравнивание на 1 байт - 8 бит
word - выравнивание на 2 байта - выравнивание на 4 байт - 16 бит
dword - выравнивание на 4 байта - 32 бит
...
Примеры с учётом, что размер кэшлайна 32 байт:
Переменная типа word - 2 байта, массив 512 - (512*2). Нужно выравнивать адрес на начало, и последующие адреса на 4 байта, почему:
При получении данных типа word - процессор будет получать данные из кэшлайна, делив на 4 байт без остатка (т.к размер кэшлайна кратен 4 байт).
Итак, если выравнивать на 4 байта, то процессор спокойно считает часть из памяти.
Если выравнивание будет пересекать границу 4 байт, то процессору нужно будет считать первую часть, вторую, а потом отбросить ненужные байты, что займёт больше времени у процессора
Другой пример - dword - массив 512 - (512*4). Выравнивать все адреса на начало, и последующие адреса на 4 байта. При получении данных процесора будет получать данные из кэшлайна, делив на 4 байт без остатка, тем самым получая сразу нужную часть.
Ещё один пример - byte (char) - массив 512 - (512*1 = 512, но 512/4, значит размер позволяет сделать выравнивание адресов на 4 байта, и процессор спокойно сможет взять нужную часть из кэшлайна).
И так далее...
В том примере с форума - речь только о dword, из-за чего ты запутался, думая, что нужно выравнивать всё на 4 байта. Моя вина. Выравнивать на 4 байта нужно только тогда, когда размер данных и кэшлайна кратен 4, дабы процессор смог сразу считать адрес из памяти, делив его на 4 без остатка. При выравнивании на 4 при размере, не кратном на 4, больше размера кэшлайна - данные попадут в соседний кэшлайн, и оставшиеся данные процессор считает как те, которые не кратны на 4, но эти потери заметны будут не сильно. При выравнивании на 4 при размере, не кратном на 4, меньше размера кэшлайна - обьект попадёт в один кэшлайн, и так же остальные данные процессор считает как те, которые были бы не кратны 4
Всё, думаю, что после этого должно всё проясниться.