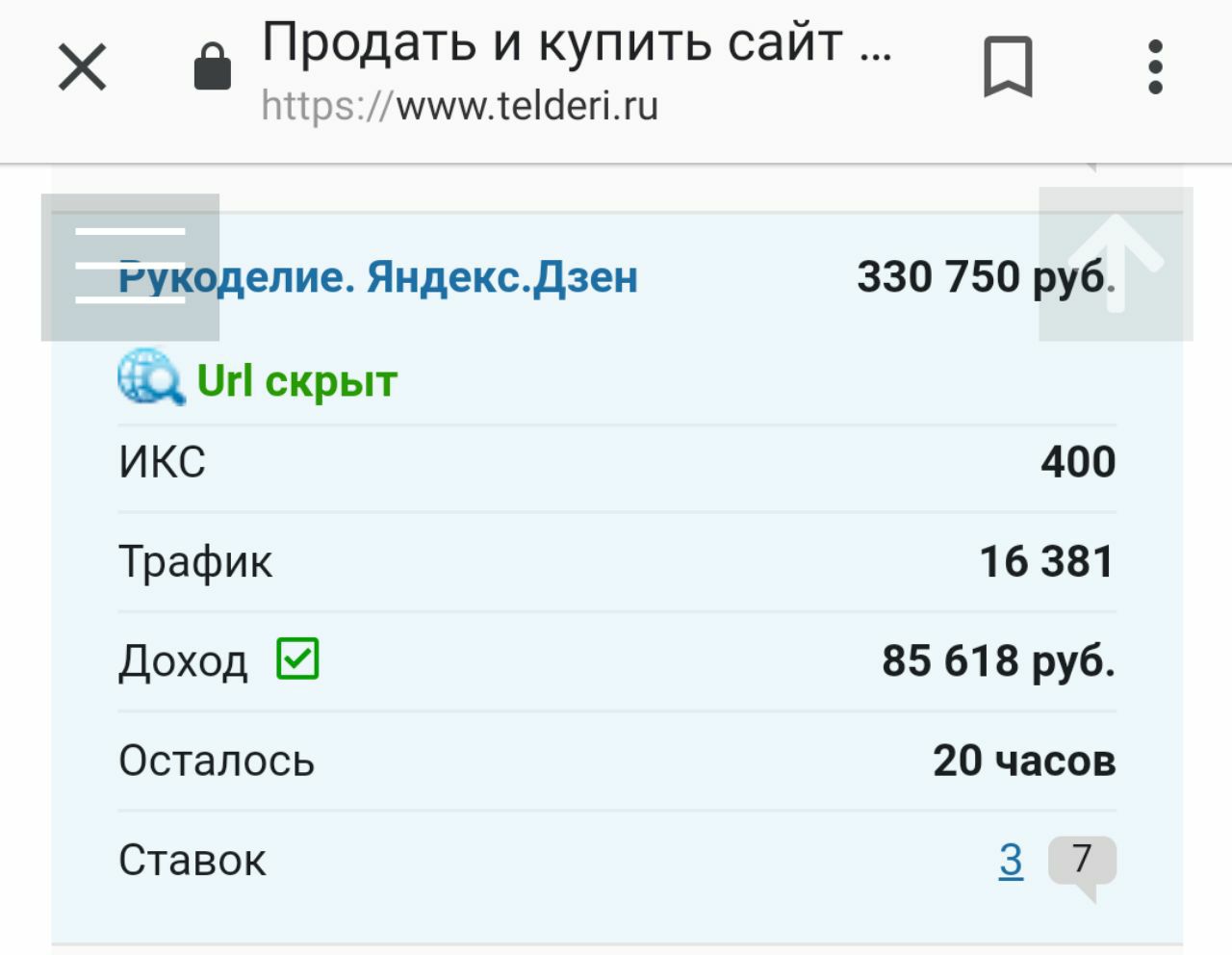
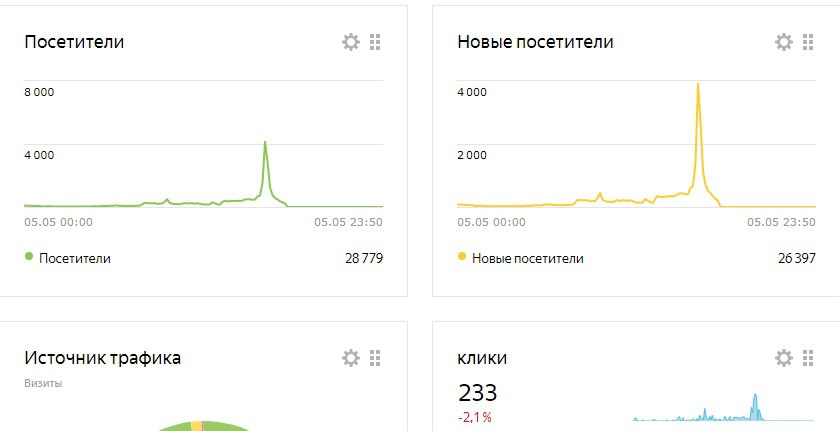
Кмк, проблема не в сравнении, а в отсутствии прозрачности.
Они же говорили: мы боимся делать алгоритм прозрачным, потому что тогда хакеры придут, тысячи статей зальют и взломают алгоритм :) Вряд ли что-то изменится в ближайшее время. А контентный спам, по моим ощущениям, определяется в том числе по схожим фоткам, популярным темам или неуникальным словарём. Если статья собрала все три (стандартное фото с поиска/стока, часто встречающееся на дзене + популярная стандартная тема (свекрови/таксисты/etc) + стандартный словарь (нет уникальных шуточек, метафор, просто живого красивого языка, etc)), она тут же улетает под контентный спам. Если два пункта из трёх — может, ещё пронесёт.