P
Еще мы сильно обновили, оздоровили, и перенесли список статей для дальнейшего обсуждения.
Он находится теперь на другой вкладке нашего расписания, посмотреть можно по ссылке
https://docs.google.com/spreadsheets/d/1ZeL1_mfR1ccwKKO_ihKs6R26pqy5bsJgU_t3jJjSN5c/edit#gid=1880412168
Там добавилось много новых статей, (в том числе и про starcraft и про теорию с ICML).
Посмотрите, пожалуйста, кого-что заинтересовало и напишите мне когда бы Вы хотели выступить.
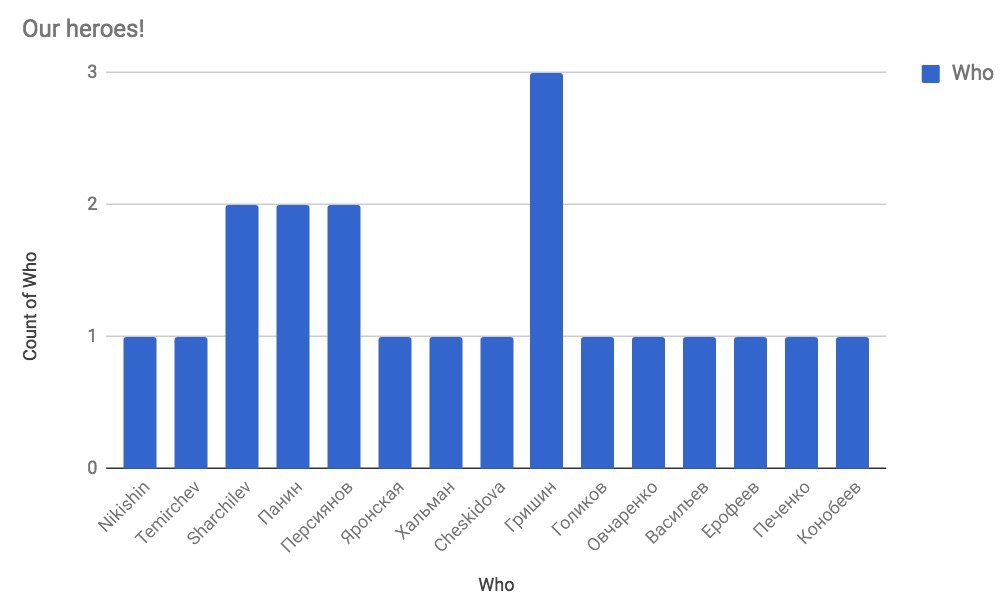
Also, у нас теперь появился красивый график героев среди наших рядов! Спасибо неизвестному создателю! 🙂
График находится на вкладке Heroes 🙂
Он находится теперь на другой вкладке нашего расписания, посмотреть можно по ссылке
https://docs.google.com/spreadsheets/d/1ZeL1_mfR1ccwKKO_ihKs6R26pqy5bsJgU_t3jJjSN5c/edit#gid=1880412168
Там добавилось много новых статей, (в том числе и про starcraft и про теорию с ICML).
Посмотрите, пожалуйста, кого-что заинтересовало и напишите мне когда бы Вы хотели выступить.
Also, у нас теперь появился красивый график героев среди наших рядов! Спасибо неизвестному создателю! 🙂
График находится на вкладке Heroes 🙂