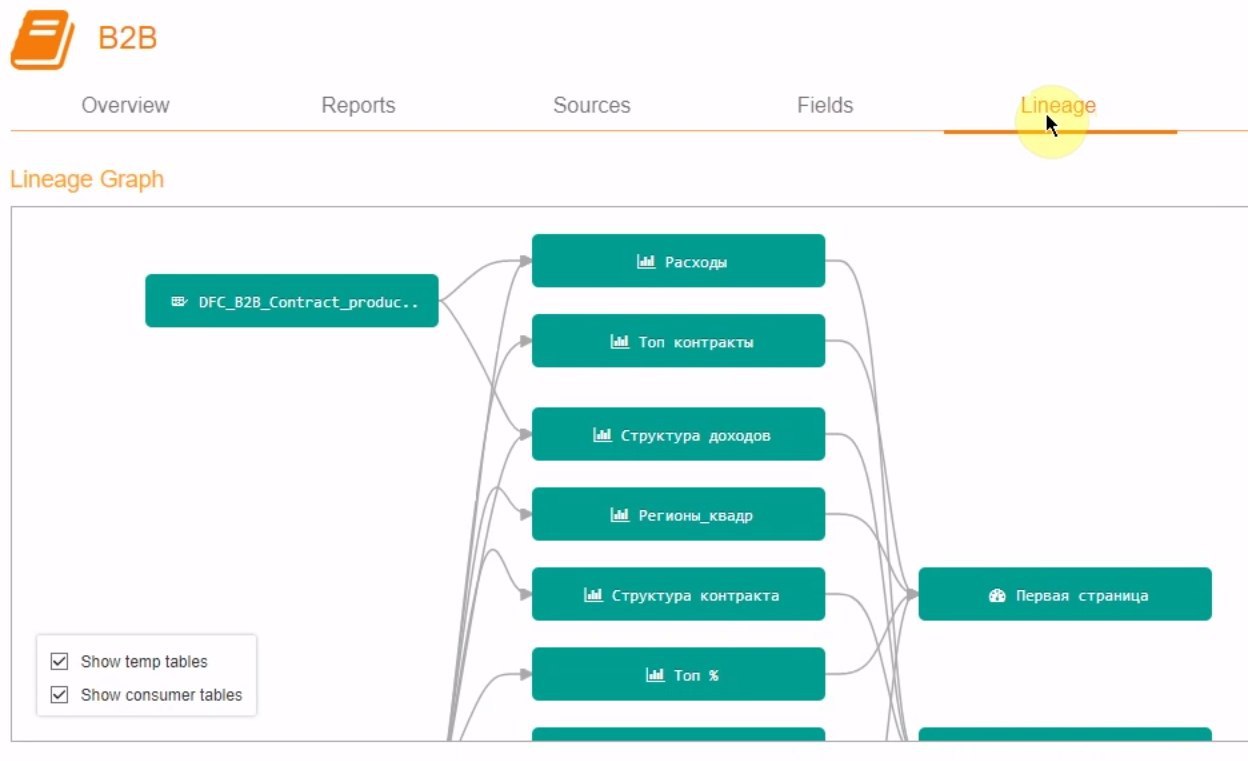
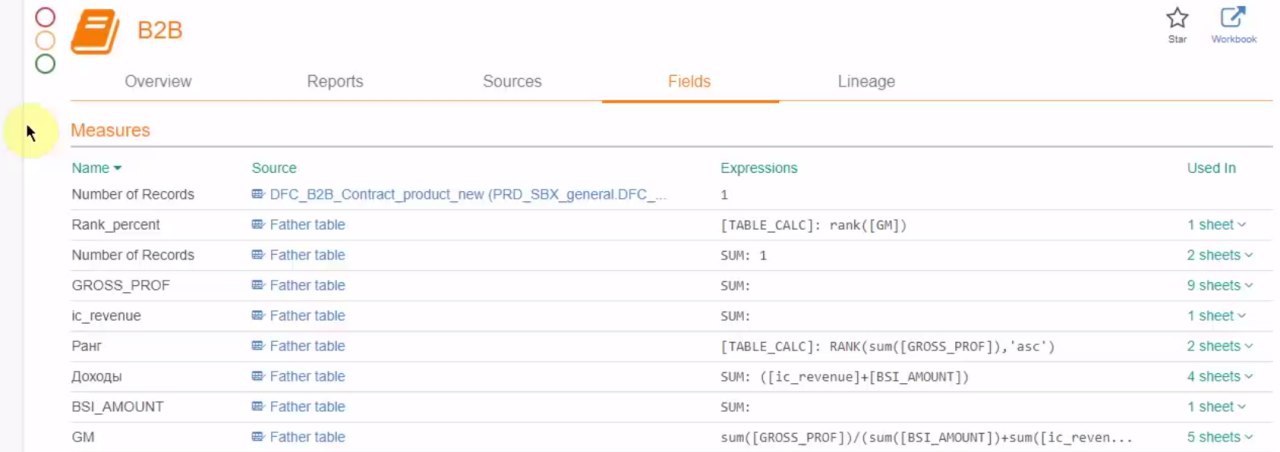
Пишешь на чем-нибудь процедуру обработки обращений к датасорсам, складываешь результат в какую-нибудь табличку, а потом ее анализируешь с целью выявить наиболее часто употребимые данные, неожиданные обращения пользователей к несвоим данным. Действительно, может интересно получиться. Но основная сложность в придумывании гипотез и их проверке, а не в хранении самой статистики.