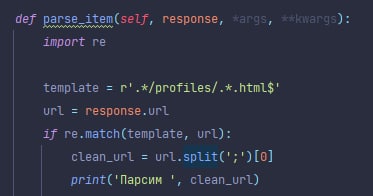
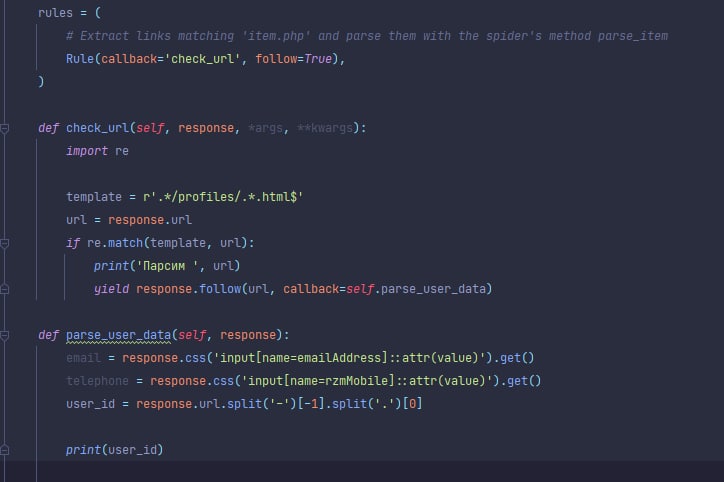
Или сразу давай такую страницу чтоб там были подходящие ссылки, или пиши ещё правила, чтоб довести паука до нужных страниц на которых есть нужные ссылки
или response.follow(clean_url) Просто ты такой базовый вопрос задаешь, что сложно представить что ты именно это спрашиваешь. Почитай туториал, там почти на первых страницах написано как делать запросы.