



iМ
Size: a a a
2020 September 30
iМ
OS
да хватит сюда скрины бросать
iМ
))
S
да хватит сюда скрины бросать
фотографии*
iМ
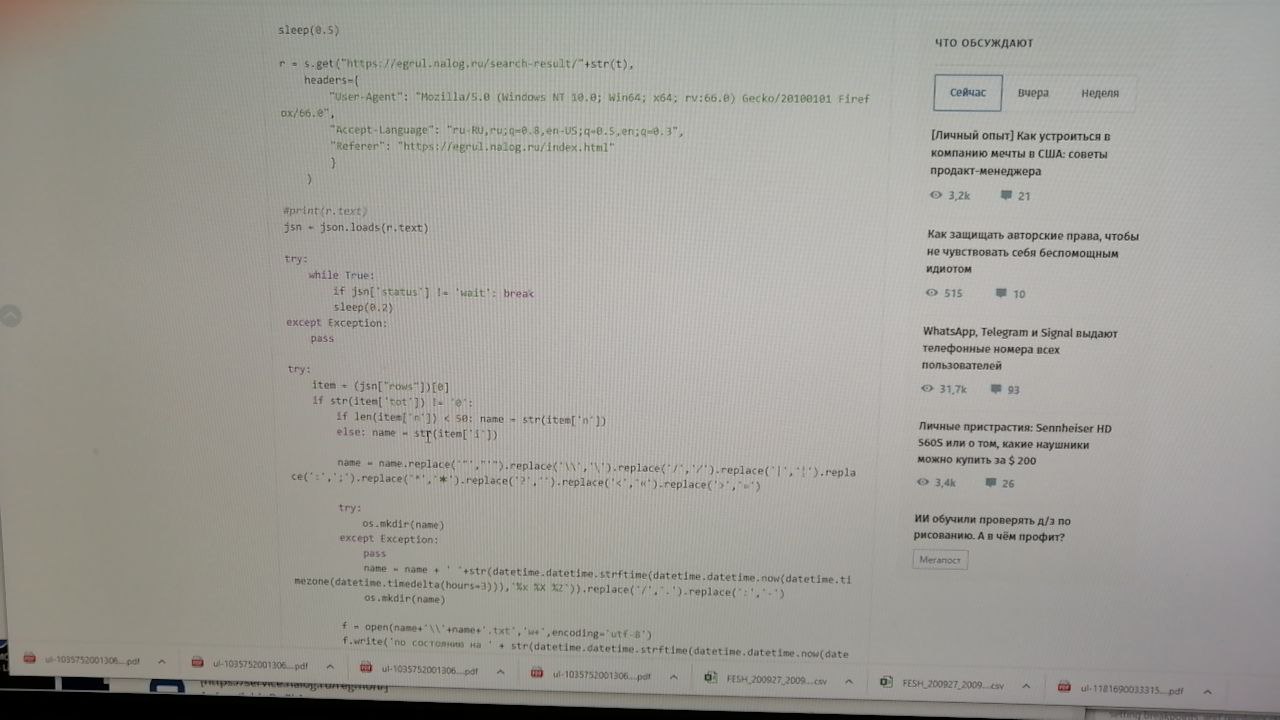
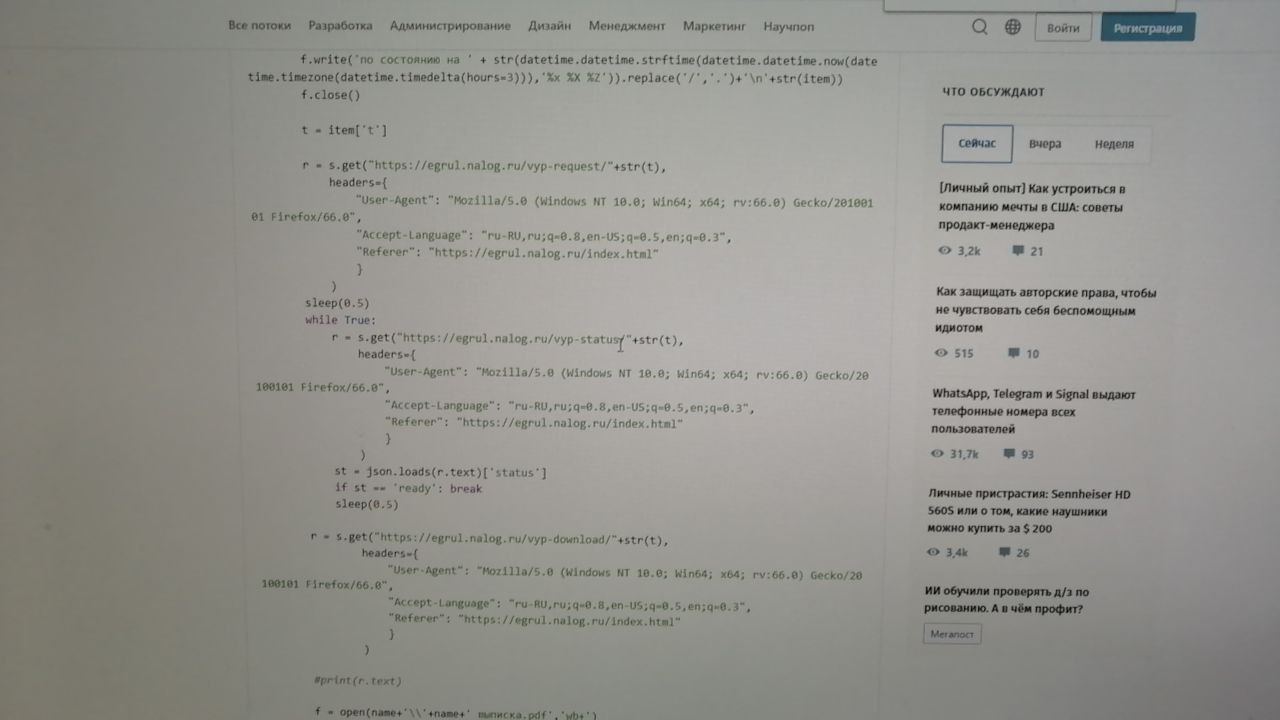
Опишу задачу. Есть сайт egrul. Там в окошечко вбивается инн, жмется кнопка и выгружается pdf файл. Это надо автоматизировать, но файлы по прежнему должны быть pdf. Сидеть выкорябывать что то из requests.get(url).content - не годится. У меня опыта тут 0. Чем лучше пользоваться, если надо поскорей что то написать. Scripy, requests или вот есть selenium.
МС
Опишу задачу. Есть сайт egrul. Там в окошечко вбивается инн, жмется кнопка и выгружается pdf файл. Это надо автоматизировать, но файлы по прежнему должны быть pdf. Сидеть выкорябывать что то из requests.get(url).content - не годится. У меня опыта тут 0. Чем лучше пользоваться, если надо поскорей что то написать. Scripy, requests или вот есть selenium.
ок, скажу по проще. egrul ты быстро не распарсишь, то что ты нашел статью на хабре - еще ничего не значит.
То что работает на одной ссылке - не факт, что будет работать на куче ссылок.
То что работает на одной ссылке - не факт, что будет работать на куче ссылок.
iМ
Вопрос цены
A
вопрос в тему фрилансеров. никто не знает группы где можно заказать дизайн?
ТЛ
Всем здравствуйте! Недавно начал работать со scrapy, мне пришлось создать свой собственный download middleware, который запрашивает хром через cdp протокол. Он возвращает HTMLResponse объект в process_request (значит, процессинг оставливается на этом этапе). Middleware хорошо работает, но когда использую его в CrawlSpider c rules, повторные вызовы больше не выполняются 🤔 Без этого middleware выполняются. Наверное что-то неправильно понял, помощь нужна)
К
Всем здравствуйте! Недавно начал работать со scrapy, мне пришлось создать свой собственный download middleware, который запрашивает хром через cdp протокол. Он возвращает HTMLResponse объект в process_request (значит, процессинг оставливается на этом этапе). Middleware хорошо работает, но когда использую его в CrawlSpider c rules, повторные вызовы больше не выполняются 🤔 Без этого middleware выполняются. Наверное что-то неправильно понял, помощь нужна)
Без кода сложно что-то посоветовать
ТЛ
Без кода сложно что-то посоветовать
Вот главное: https://pastebin.com/PLcvWPeY

AR
что такое повторные вызовы?
ТЛ
Callback
AR
что callback?
ТЛ
В коде это parse_item
AR
ты называешь колбэки повторными вызовами или что?
ТЛ
Да 😬 Русский - не мой родной язык
AR
окей, и что происходит?