YB
https://pastebin.com/M8cSG59T
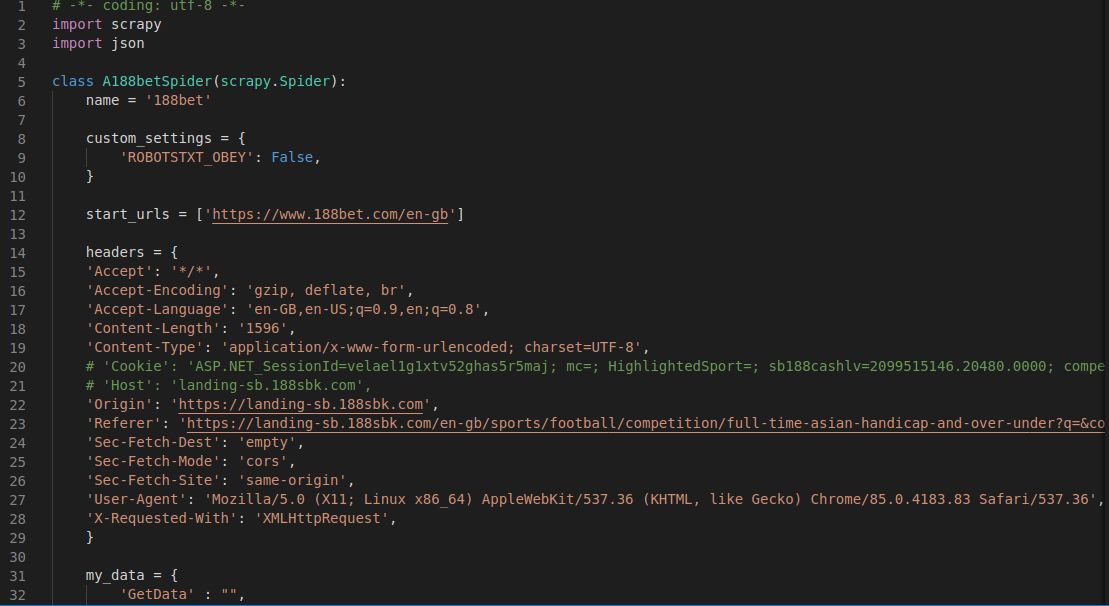
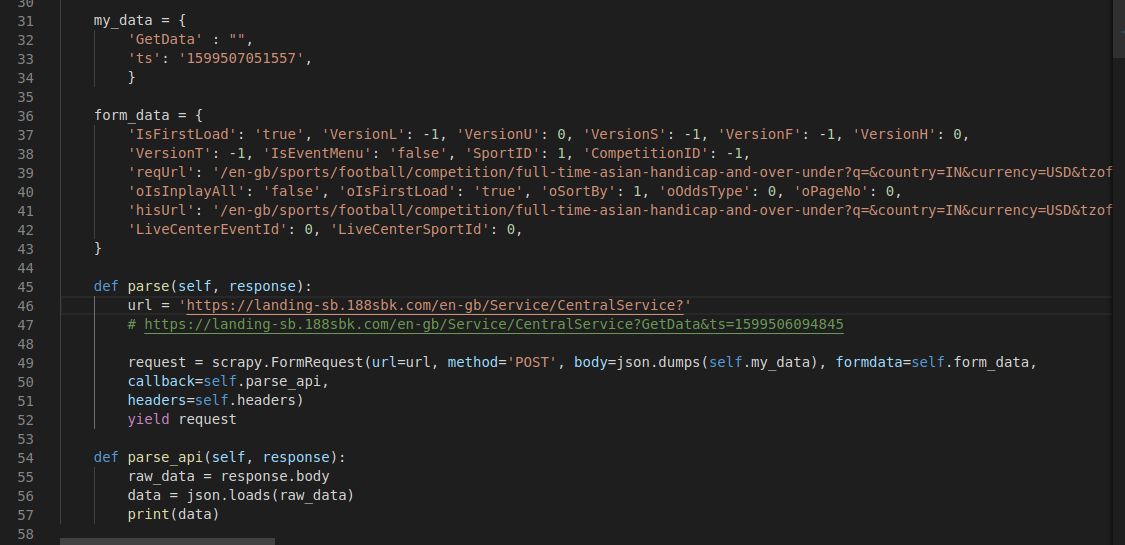
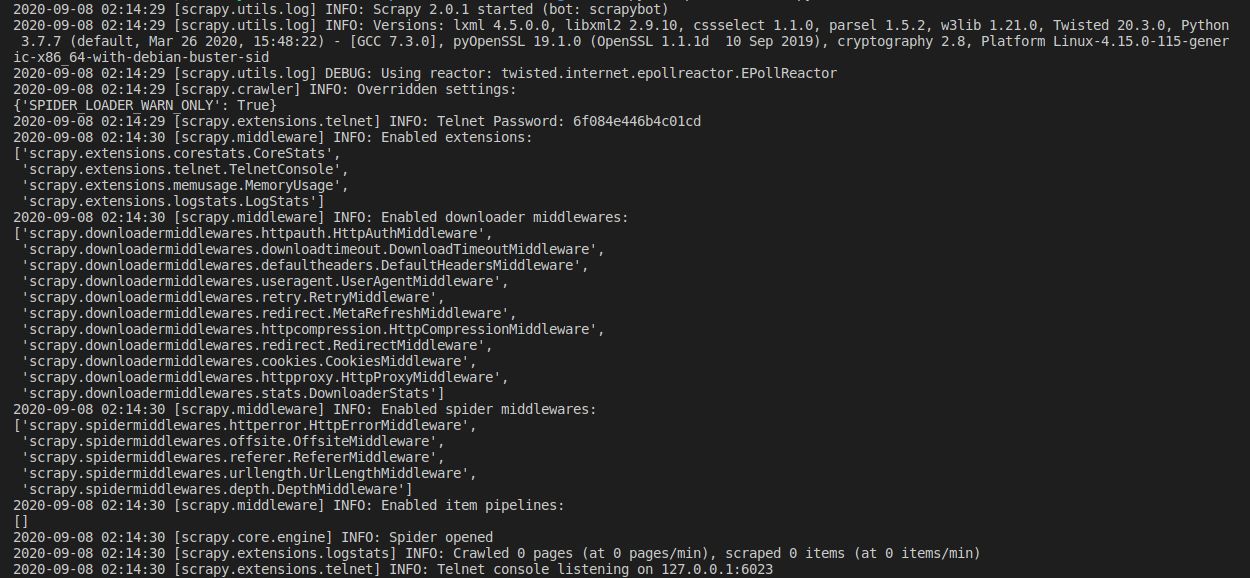
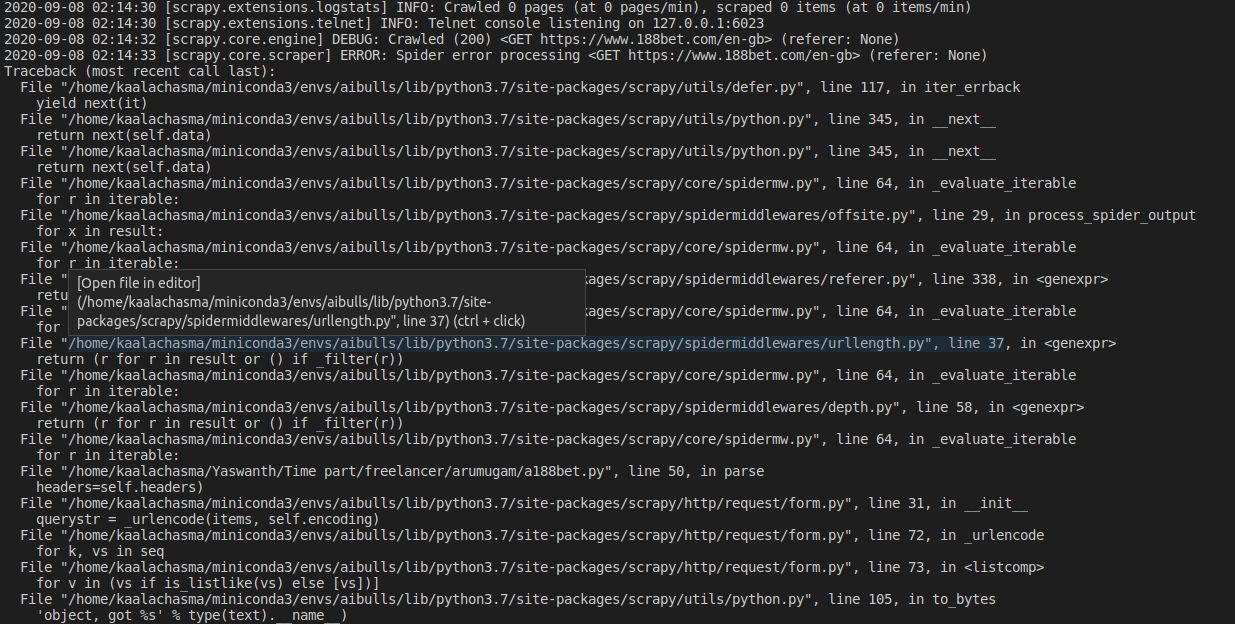
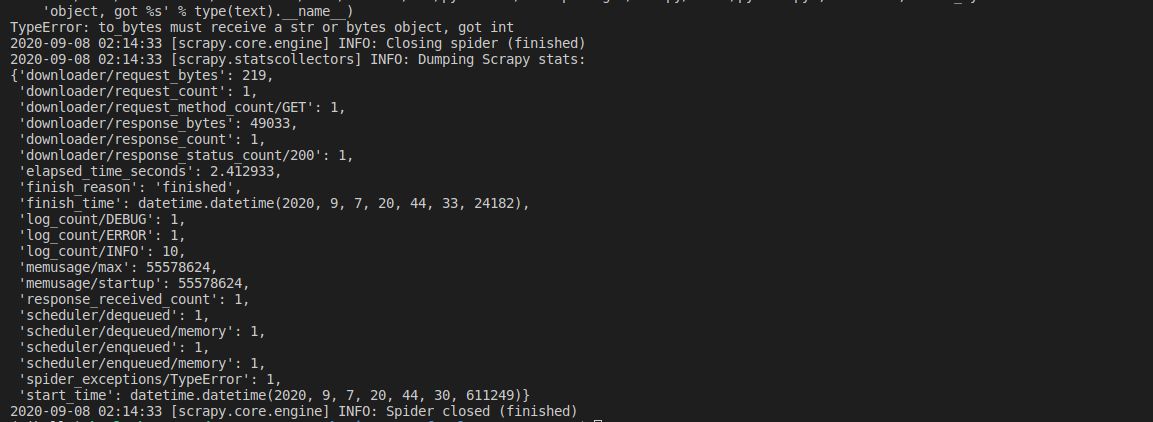
I am trying to print the json response of an xhr post request, I literally gave the scrapy FormRequest everything the browser does, as in almost all the necessary Request Headers, Form Data (pretty much as it is, didn't leave anything) and Query String Parameters as well. When I run the spider, it throws as error " 'object, got %s' % type(text).__name__)" . When I looked into it, the potential resolution was to use the custom setting 'ROBOTSTXT_OBEY' : False in the custom settings dict in the spider. It's not helping however, can someone help me figure out where am I wrong?
The actual link I am trying to fetch the json from is
https://www.188bet.com/en-gb/sports/football/competition/full-time-asian-handicap-and-over-under?competitionids=26726,26326,27325,26470,26766,72584,72585,72586,72587,28288,27760,27068,27487,29490,27436,38803,29198,27111,32599,72684,26854,26664,29083,30674,27938,43960,27202,29061,99368,26146,28586,26919,29274,28649,29045,26216,26713,27904,26538,46886,28366,26380,29599,27099,26213,26814,26526,28487,26619,29042,27161,41440,26218,26986,27780,26408,26862,103068,28571
.
I am trying to print the json response of an xhr post request, I literally gave the scrapy FormRequest everything the browser does, as in almost all the necessary Request Headers, Form Data (pretty much as it is, didn't leave anything) and Query String Parameters as well. When I run the spider, it throws as error " 'object, got %s' % type(text).__name__)" . When I looked into it, the potential resolution was to use the custom setting 'ROBOTSTXT_OBEY' : False in the custom settings dict in the spider. It's not helping however, can someone help me figure out where am I wrong?
The actual link I am trying to fetch the json from is
https://www.188bet.com/en-gb/sports/football/competition/full-time-asian-handicap-and-over-under?competitionids=26726,26326,27325,26470,26766,72584,72585,72586,72587,28288,27760,27068,27487,29490,27436,38803,29198,27111,32599,72684,26854,26664,29083,30674,27938,43960,27202,29061,99368,26146,28586,26919,29274,28649,29045,26216,26713,27904,26538,46886,28366,26380,29599,27099,26213,26814,26526,28487,26619,29042,27161,41440,26218,26986,27780,26408,26862,103068,28571
.