Конкретно последний сайт с капча челенжом, но cfscrape раньше в таком случае просто падал с ошибкой, что он не умеет решать капчи. Перед этим был сайт с js челенжом, там решение давал, но ничего не происходило потом
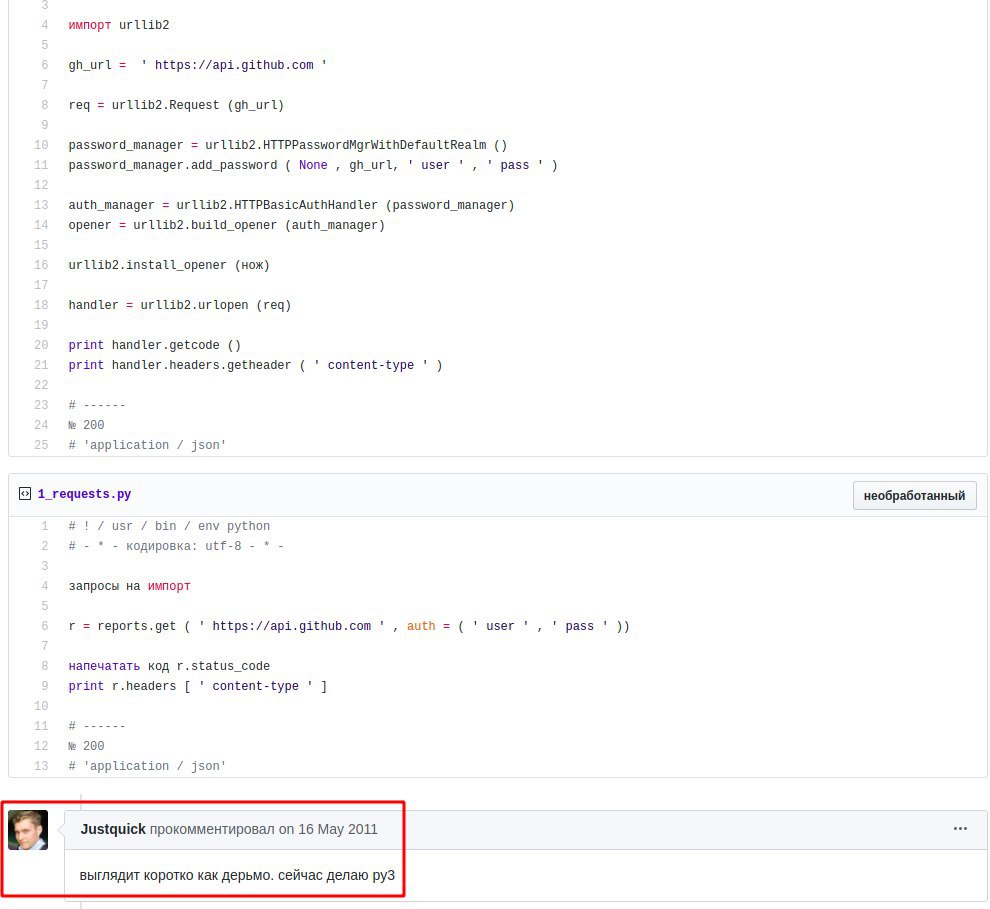
ребят, юзает ещё кто-то urllib? Просто читаю книгу по скрапингу и там работа с этой либой, хотя есть ведь вариант попроще, тот же requests к примеру, если напрямую вызывать