



SN
Size: a a a
2020 April 03
AD
Спасибо большое
Не за что


2020 April 10
DM
16 апреля марта в 12.00 по московскому времени мы проведем вебинар на русском языке, где расскажем, как получить оптимальный инференс на NVIDIA GPU.
На вебинаре вы узнаете, что такое фреймворк TensorRT и как он ускоряет нейросети. Мы также покажем, как расширять NVIDIA TensorRT пользовательскими слоями с использованием CUDA и вместе имплементируем кастомный CoordConv слой в PyTorch и TensorRT для ускоренного инференса.
Спикер - Денис Тимонин, NVIDIA Solutions Architect AI for Russia & CIS
Длительность вебинара - 2 часа.
Для участия в вебинаре, пожалуйста, зарегистрируйтесь: https://bit.ly/2Ve1OrJhttps://bit.ly/2Ve1OrJ
На вебинаре вы узнаете, что такое фреймворк TensorRT и как он ускоряет нейросети. Мы также покажем, как расширять NVIDIA TensorRT пользовательскими слоями с использованием CUDA и вместе имплементируем кастомный CoordConv слой в PyTorch и TensorRT для ускоренного инференса.
Спикер - Денис Тимонин, NVIDIA Solutions Architect AI for Russia & CIS
Длительность вебинара - 2 часа.
Для участия в вебинаре, пожалуйста, зарегистрируйтесь: https://bit.ly/2Ve1OrJhttps://bit.ly/2Ve1OrJ
rd
16 апреля марта в 12.00 по московскому времени мы проведем вебинар на русском языке, где расскажем, как получить оптимальный инференс на NVIDIA GPU.
На вебинаре вы узнаете, что такое фреймворк TensorRT и как он ускоряет нейросети. Мы также покажем, как расширять NVIDIA TensorRT пользовательскими слоями с использованием CUDA и вместе имплементируем кастомный CoordConv слой в PyTorch и TensorRT для ускоренного инференса.
Спикер - Денис Тимонин, NVIDIA Solutions Architect AI for Russia & CIS
Длительность вебинара - 2 часа.
Для участия в вебинаре, пожалуйста, зарегистрируйтесь: https://bit.ly/2Ve1OrJhttps://bit.ly/2Ve1OrJ
На вебинаре вы узнаете, что такое фреймворк TensorRT и как он ускоряет нейросети. Мы также покажем, как расширять NVIDIA TensorRT пользовательскими слоями с использованием CUDA и вместе имплементируем кастомный CoordConv слой в PyTorch и TensorRT для ускоренного инференса.
Спикер - Денис Тимонин, NVIDIA Solutions Architect AI for Russia & CIS
Длительность вебинара - 2 часа.
Для участия в вебинаре, пожалуйста, зарегистрируйтесь: https://bit.ly/2Ve1OrJhttps://bit.ly/2Ve1OrJ
> 16 апреля марта
=)
=)
DM
> 16 апреля марта
=)
=)
ой. сорри. поправил. спасибо!
rd
ой. сорри. поправил. спасибо!
Не за что =)
2020 April 17
DM
16 апреля марта в 12.00 по московскому времени мы проведем вебинар на русском языке, где расскажем, как получить оптимальный инференс на NVIDIA GPU.
На вебинаре вы узнаете, что такое фреймворк TensorRT и как он ускоряет нейросети. Мы также покажем, как расширять NVIDIA TensorRT пользовательскими слоями с использованием CUDA и вместе имплементируем кастомный CoordConv слой в PyTorch и TensorRT для ускоренного инференса.
Спикер - Денис Тимонин, NVIDIA Solutions Architect AI for Russia & CIS
Длительность вебинара - 2 часа.
Для участия в вебинаре, пожалуйста, зарегистрируйтесь: https://bit.ly/2Ve1OrJhttps://bit.ly/2Ve1OrJ
На вебинаре вы узнаете, что такое фреймворк TensorRT и как он ускоряет нейросети. Мы также покажем, как расширять NVIDIA TensorRT пользовательскими слоями с использованием CUDA и вместе имплементируем кастомный CoordConv слой в PyTorch и TensorRT для ускоренного инференса.
Спикер - Денис Тимонин, NVIDIA Solutions Architect AI for Russia & CIS
Длительность вебинара - 2 часа.
Для участия в вебинаре, пожалуйста, зарегистрируйтесь: https://bit.ly/2Ve1OrJhttps://bit.ly/2Ve1OrJ
Запись вебинара "NVIDIA TensorRT: Оптимальный инференс нейросетей на GPU", слайды, а также выгрузку Q&A вы найдете по ссылке: https://bit.ly/2XILxhi
Также, запись вебинара можно посмотреть в нашей группе в VK: https://vk.com/nvidiadeveloper
Также, запись вебинара можно посмотреть в нашей группе в VK: https://vk.com/nvidiadeveloper
2020 April 23
AB
Удалил тут опять рекламировали услуги
2020 April 27
AB

ZO
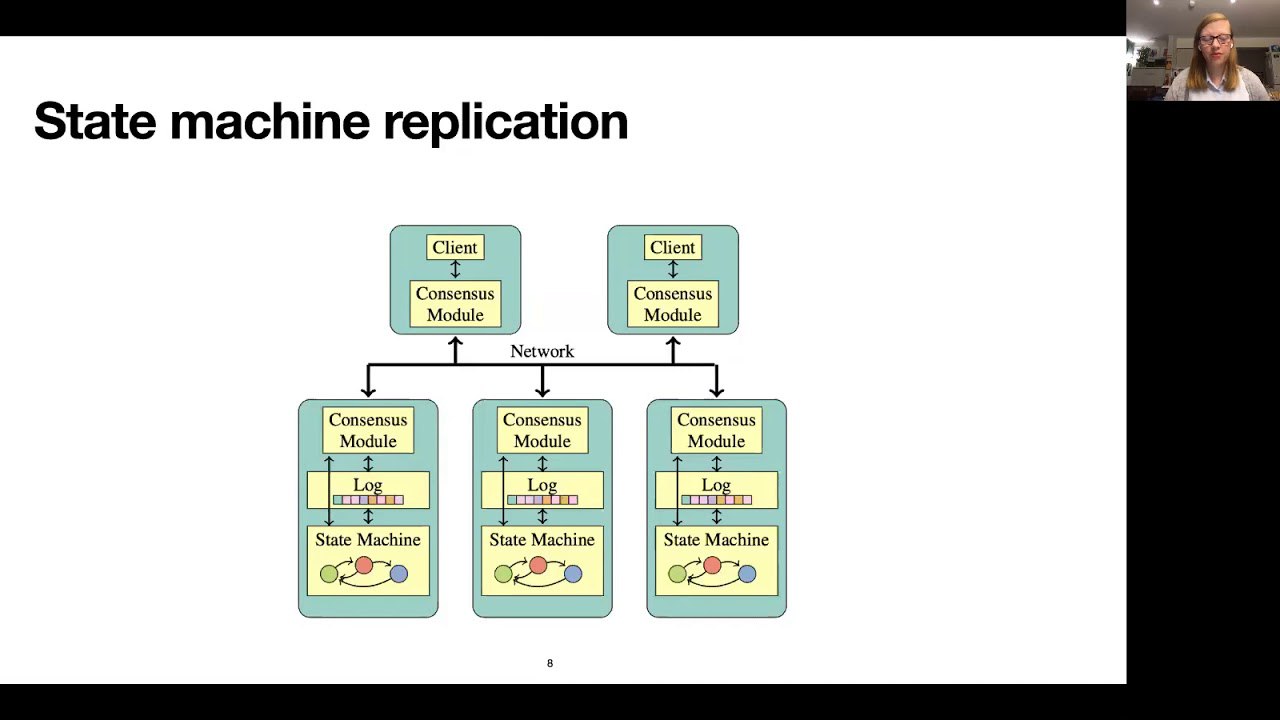
Разве в рафте не нашли ошибку?
S
Разве в рафте не нашли ошибку?
;) а нашли? можно пруфы?
SF
А в каких продакшен системах paxos вообще применяется? Все системы, которые у меня на слуху, используют рафт или что-то рафтоподобное
C
2020 April 28
AK
Новость одной строкой: вышла новая версия стандарта OpenCL 3.0 для параллельных вычислений на разных мультиядерных устройствах. В отличие от nVidia CUDA, которая работает только на GPU nVidia, OpenCL может использоваться на GPU от AMD и nVidia + на многоядерных CPU (то есть вообще на всех современных процессорах, даже ARM).
https://www.khronos.org/registry/OpenCL/
https://www.khronos.org/registry/OpenCL/
AK
Новость одной строкой: вышла новая версия стандарта OpenCL 3.0 для параллельных вычислений на разных мультиядерных устройствах. В отличие от nVidia CUDA, которая работает только на GPU nVidia, OpenCL может использоваться на GPU от AMD и nVidia + на многоядерных CPU (то есть вообще на всех современных процессорах, даже ARM).
https://www.khronos.org/registry/OpenCL/
https://www.khronos.org/registry/OpenCL/
Кто-то смотрел уже?
Не стала секси как куда?
Не стала секси как куда?
AB
Да но пока не нашел релизации