#cloudmigration
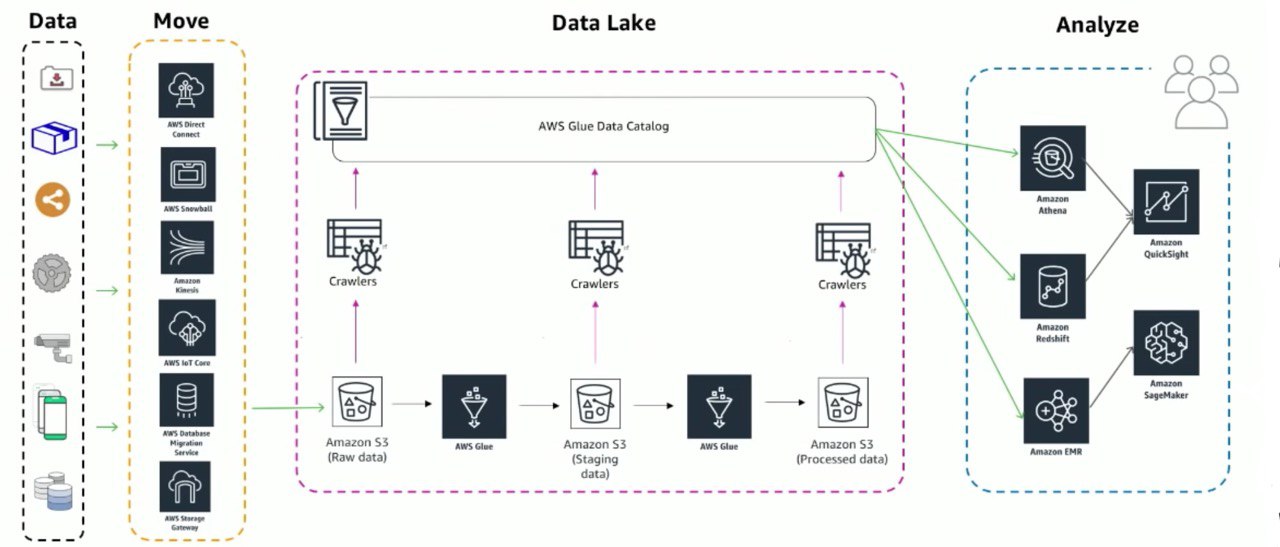
Создание инфраструктуры в облаке или миграция в облако это уже не тренд, это факт. Как обычно выглядит миграция в облако? Мы создаем себе аккаунт, запускаем необходимые сервисы, настраиваем безопасность и доступ. Остается последний шаг, загрузить наши данные в облако. Мы можешь загружать терабайты данных без проблем. Но как быть с петабайтами? Например, загрузка 100 терабайт при скорости загрузки 1 Gbps, займет 100 дней.
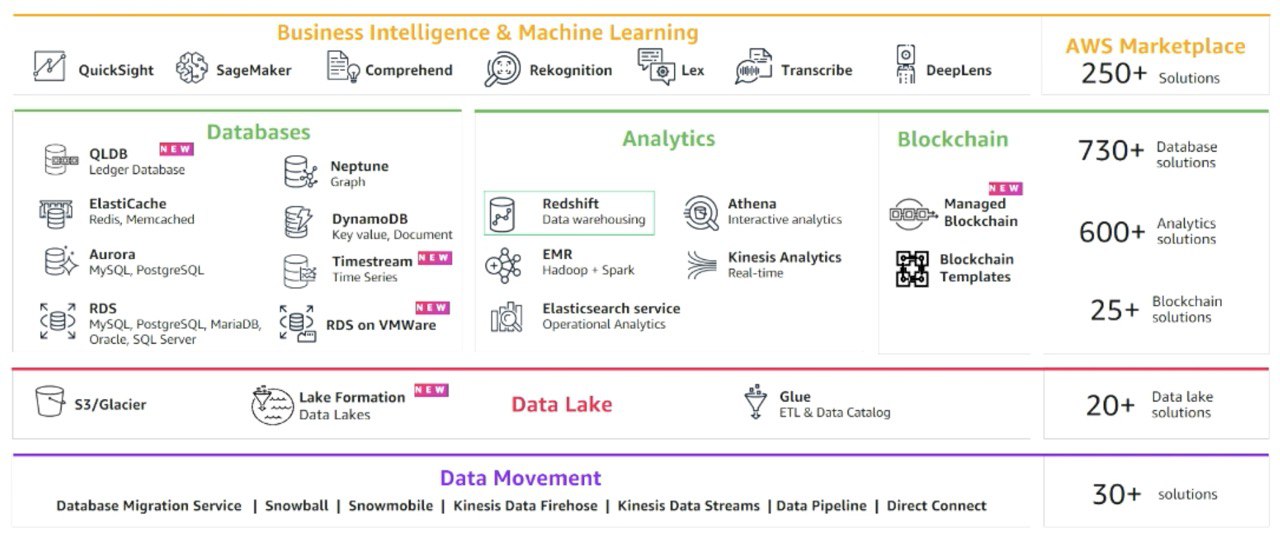
Специально для таких случаев у AWS есть 2 продукта. Когда в 2016 году re:Invest (главный AWS саммит) представили Snowmobile, я думал это шутка, а вот нет. Хотите в облако, к вам приезжает грузовик и вы загружаете данные, затем он их перевозит в дата центр Амазон. 1 грузовик вмещает до 100 петабайт данных и закачивать он будет несколько недель. А вот при скорости 1 Gbps, займет 20 лет. Это вам не фильмы с торрентов качать🤞 (кстати в Канаде тоже все не просто с торрентами, могут и штраф прислать).
Недавно, AWS выпустил еще один продукт Snowball – тоже физический носитель данных, но уже помещается в сумке.
А вот видео с грузовиком https://youtu.be/8vQmTZTq7nw
Создание инфраструктуры в облаке или миграция в облако это уже не тренд, это факт. Как обычно выглядит миграция в облако? Мы создаем себе аккаунт, запускаем необходимые сервисы, настраиваем безопасность и доступ. Остается последний шаг, загрузить наши данные в облако. Мы можешь загружать терабайты данных без проблем. Но как быть с петабайтами? Например, загрузка 100 терабайт при скорости загрузки 1 Gbps, займет 100 дней.
Специально для таких случаев у AWS есть 2 продукта. Когда в 2016 году re:Invest (главный AWS саммит) представили Snowmobile, я думал это шутка, а вот нет. Хотите в облако, к вам приезжает грузовик и вы загружаете данные, затем он их перевозит в дата центр Амазон. 1 грузовик вмещает до 100 петабайт данных и закачивать он будет несколько недель. А вот при скорости 1 Gbps, займет 20 лет. Это вам не фильмы с торрентов качать🤞 (кстати в Канаде тоже все не просто с торрентами, могут и штраф прислать).
Недавно, AWS выпустил еще один продукт Snowball – тоже физический носитель данных, но уже помещается в сумке.
А вот видео с грузовиком https://youtu.be/8vQmTZTq7nw