



MB
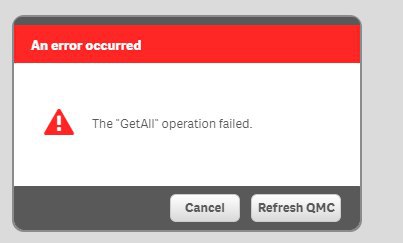
Всем привет! Кто-нибудь сталкивался с такой ошибкой? Появляется при попытке заменить опубликованное приложение. В Community нашла, что дело может быть в нехватке оперативной памяти, но памяти достаточно.
Size: a a a
MB
ЕС
ZS
DS
GV
DS
DS
DS
ЕС
DS
DS
DS
DS
ЕС
DS
ZS
DS
ZS
ZS
ZS