Репост из канала
Данилы Кутенина (орфография и пунктуация автора) про тестирование движка для регулярных выражений:
В последние 2 недели периодически, когда мне было лень работать, я пытался сделать что-то интересное, но до большого и громкого поста не дотягивало. В любом случае, поделиться стоит.
Меня задолбали различные движки регулярных выражений и каждый раз, когда я смотрел на них, мне хотелось понять, как они под капотом тестируются. После изучения многих библиотек, я понял, что поддержка огромного количества токенов так грустно покрыто юнит тестами, что я захотел либо найти достойное тестирование (спойлер, не нашёл), либо десятки багов в этих движках. Суммарно за несколько дней я нашёл
11 багов, 2 в boost (уже были зарепорчены
1,
2),
4 новых в hyperscan,
5 новых в compile time regular expressions (будущие regex в плюсовом стандарте) и огромное количество (нет, просто капец тьму) несоответствия между синтаксисами различных движков, например, что в
RE2 синтаксисе whitespace (\s) не поддерживается вертикальный tab \v, хотя во всех остальных движках оно одинаково поддерживается. Или даже лучше (не баг, различие в грамматиках):
#include <boost/regex.hpp>
#include <regex>
#include <iostream>
int main() {
{
std::regex e{"\\<\\<\\w+"};
std::cout << std::regex_search("a ", e) << std::endl; // prints 0
}
{
boost::regex e{"\\<\\<\\w+"};
std::cout << boost::regex_search("a ", e) << std::endl; // prints 1
}
}
Python RE,
PCRE/PCRE2,
RE2 прошли тестирование. Видимо, big tech является для них самым главным тестировщиком :)
В отличие от стандартного тестирования, я пытался сделать что-то новое, а именно
1. Создаем случайное валидное регулярное выражение, например, с помощью случайного дерева или автомата
2. Если движок отказывается его компилировать, это баг. Можно здесь ещё считать majority от движков и репортить те, которые не подчиняются ему
3. Создаем строки подходящие под это регулярное выражение, если они не матчатся, то это баг. Создаём почти подходящие строки, если они матчатся, это баг. Здесь я использовал идеи из статьи
egret и питонячнее
.sre_parse
4. Фаззим с помощью
libfuzzer входные строки для поиска, пытаемся найти рантайм баги и сверяем корректность у majority движков
У многих движков настроен фаззинг, только они не
проверяют полноту. К счастью, видимо, весь хлеб такого тестирования фаззинг у меня и забрал, мой план лишь быстрее увеличивал покрытие. Например, такой план увеличивал покрытие hyperscan до 90% за 2 часа, когда как обычный фаззинг делал это 3 дня.
Несмотря на баги,
hyperscan всё ещё считаю лучшим движком by far от всех остальных. Там очень много очень классного кода, написано хорошо, работает очень быстро (сотни мегабайт в секунду). Недавно узнал, что там можно собирать регулярные выражения в
satisfiability дерево, например, в
((1 & 2) | (!3 & 2)), где 1, 2, 3 — регулярные выражения. Так они ещё там внутри и оптимизируются.
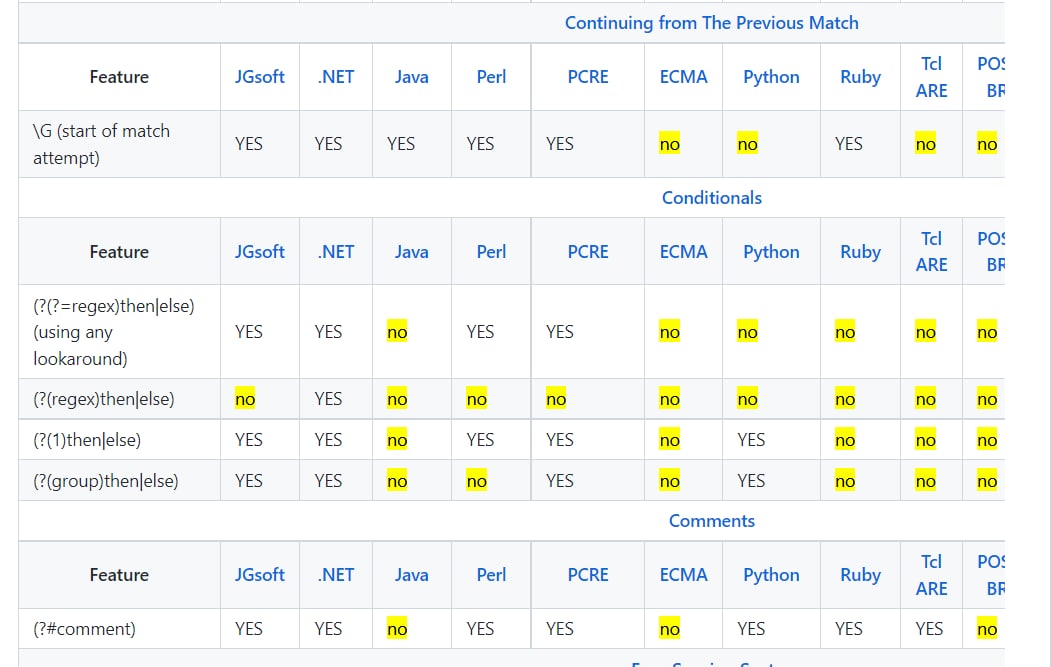
Если говорить про различие синтаксисов, то есть
неплохая табличка.
Ну, 11 багов, that ain't much but that's honest work. Надеялся на много десятков минимум :)