KY
да мы вроде и не про открытую и закрытую модель.
моя ключевая часть позиции - проблема интерпретации. это к тому, что в отчетах хотят писать юзеров чтобы показывать бизнесу.
но данная хотелка заставляет пилить скрипты через нагрузку в тредах. что ЧАСТО (не всегда) приводит к сценарному подходу.
отсюда на всех уровнях есть проблемы:
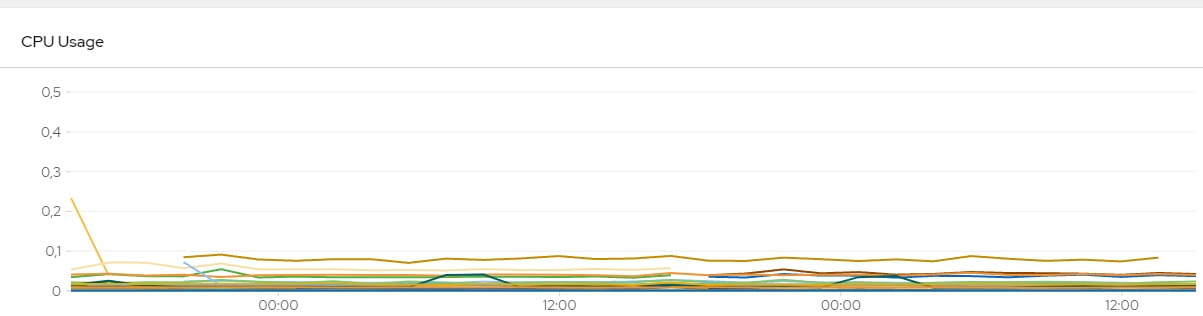
1. в отчете - у тебя будет цифра в юзерах, это то количество которое держит твоя система, например в поиске максимума. тогда твой бизнес думает: "ок если к нам придет больше юзеров значит мы не выдержим", но это не так, потому что юзеры, которых мы реализуем в скриптах не равны реальным. тогда зачем обманывать бизнес, даже если он этого сам хочет?
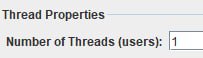
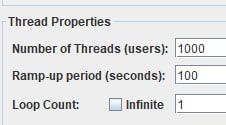
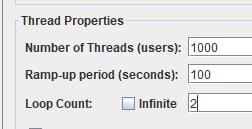
2. в реализации нагрузки через треды появляется тоже кучу проблем - мало кто мыслит в юзерах рассматривая их в сумме. народ пилит сценарий и потом скейлит его в то количество, которое видит в системе или в другой косвенной метрике - тем самым упрощая реализацию, но теряя в точности. но даже если в тредах пытаются учесть распределение и рпсы операций с прода - то этим подходом сильно усложняют разработку, тем самым в любом случае вынуждены реализовывать закрытую модель во-первых и при поддержке нужно апдейтить две зависимые метрики рпс+треды, что вызвано только желанием отражать треды в отчетах.
поэтому я комплексно не понимаю, зачем люди именно пропагандируют этот подход.
моя ключевая часть позиции - проблема интерпретации. это к тому, что в отчетах хотят писать юзеров чтобы показывать бизнесу.
но данная хотелка заставляет пилить скрипты через нагрузку в тредах. что ЧАСТО (не всегда) приводит к сценарному подходу.
отсюда на всех уровнях есть проблемы:
1. в отчете - у тебя будет цифра в юзерах, это то количество которое держит твоя система, например в поиске максимума. тогда твой бизнес думает: "ок если к нам придет больше юзеров значит мы не выдержим", но это не так, потому что юзеры, которых мы реализуем в скриптах не равны реальным. тогда зачем обманывать бизнес, даже если он этого сам хочет?
2. в реализации нагрузки через треды появляется тоже кучу проблем - мало кто мыслит в юзерах рассматривая их в сумме. народ пилит сценарий и потом скейлит его в то количество, которое видит в системе или в другой косвенной метрике - тем самым упрощая реализацию, но теряя в точности. но даже если в тредах пытаются учесть распределение и рпсы операций с прода - то этим подходом сильно усложняют разработку, тем самым в любом случае вынуждены реализовывать закрытую модель во-первых и при поддержке нужно апдейтить две зависимые метрики рпс+треды, что вызвано только желанием отражать треды в отчетах.
поэтому я комплексно не понимаю, зачем люди именно пропагандируют этот подход.