



AK
Svetlana
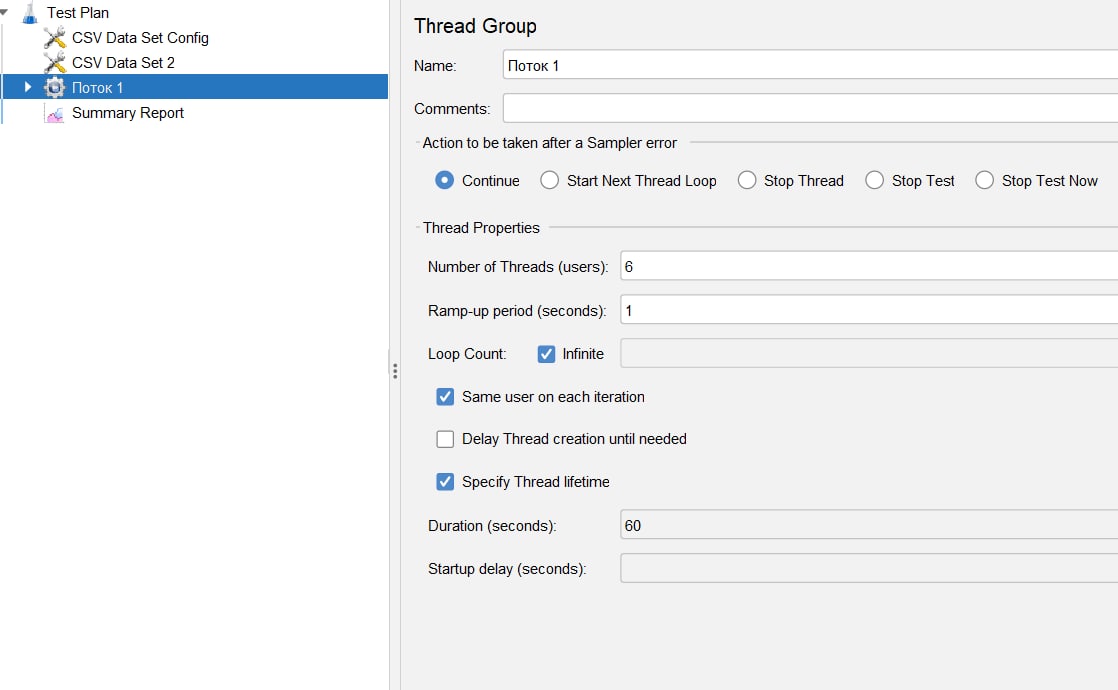
Всем привет!
У меня есть набор запросов, объединенных в Thread Group. Есть файл csv, в котором 3 значения для Параметр1. Мне нужно, чтобы все время выполнялось 2 потока для каждого значения из файлика. Т.е. запустились по 2 потока для каждого значения, далее когда завершится первый из них например для значения1, должен сразу появиться новый поток для этого значения. Как завершится второй - сразу появится еще один. И так на протяжении определенного времени.
Верно ли сделала? Или нужно как-то по-другому?
У меня есть набор запросов, объединенных в Thread Group. Есть файл csv, в котором 3 значения для Параметр1. Мне нужно, чтобы все время выполнялось 2 потока для каждого значения из файлика. Т.е. запустились по 2 потока для каждого значения, далее когда завершится первый из них например для значения1, должен сразу появиться новый поток для этого значения. Как завершится второй - сразу появится еще один. И так на протяжении определенного времени.
Верно ли сделала? Или нужно как-то по-другому?
А что в цсв дата сет конфигах, как они настроены?
