NM
Всем привет!
Дано(jmeter):
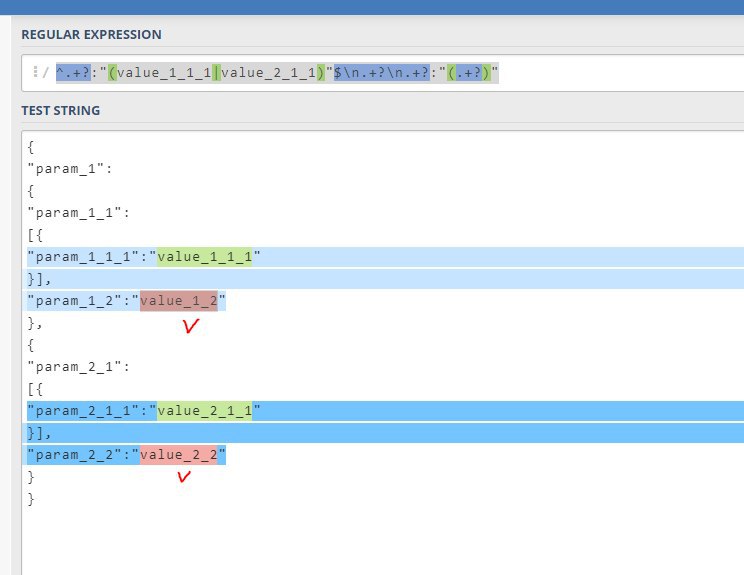
1. Запрос, который возвращает json вида
{
"param_1":
{
"param_1_1":
[{
"param_1_1_1":"value_1_1_1"
}],
"param_1_2":"value_1_2"
},
{
"param_2_1":
[{
"param_2_1_1":"value_2_1_1"
}],
"param_2_2":"value_2_2"
}
}
(*json очень огромный возвращается, привёл его урезанный пример)
Задача такая, вытянуть значения "value_1_2" и "value_2_2", зная значения потомков "value_1_1_1", "value_2_1_1"
Пробовал применить json extractor, но в его регулярку можно запихнуть одну строку, использовав при этом либо "value_1_1_1" либо "value_2_1_1", и результат его работы запихнуть в переменную; притом знаю, что json extractor умеет работать только с ответом от запроса
В связи с этим вопрос, что можно применить? какой нибудь dummy-запрос, куда запихать ещё и post processor какой нибудь beanshell, для применения математики? тогда как лучше ответ от запроса "тягать" по скрипту и использовать когда надо?