



ΙΤ
Size: a a a
2020 June 07
ΙΤ
Сори не инфлакс а графана
ΙΤ
В GrayLog, как Иоанн советует, можно класть тела ответов, он разбухнет, но переварит. А InfluxDB разбухнет и зависнет.
И я кстати не про грейлог а про gelf формат
ВС
И я кстати не про грейлог а про gelf формат
Пока не знаком с gelf
ВС
Для больших данных и обработки данных с диска есть решение в виде ClickHouse. Он сжимает данные, хорошо читает с диска за счёт колоночной структуры. Поэтому быстр. Но на нём надо будет научиться программировать, у него специфичные функции. С ним можно логи долго не удалять и хранить подробную историю всего. Ещё не пробовал в бою, просто присматриваюсь.
Pandas хорош для вычислений в оперативной памяти, он загружает весь DataFrame в ОЗУ. Ему надо много ОЗУ, работает он быстро. Пробовал в бою. Если данные в ОЗУ не поместятся, то включится gc, обработка замедлится или вообще будет не возможна. На практике во время загрузки данных выполнялся их парсинг, чтобы сырые данные превратить в статистику, которая влежает в ОЗУ.
ElasticSearch не сжимает данные, имеет быстрый и удобный поисковый движок, но требует много места на диске под индексы. Поэтому там логи больше недели не хранят. Он для оперативного разбора данных за последнюю неделю.
InfluxDB хорош для хранения статистики, а не для сырых данных. В него загружаю статистику по логам - сколько было таких текстов (тегов) за 5 минут. А не все тексты за 5 минут. Статистику можно создать в awk, python + pandas, csvkit, чем-либо другом. Такой объем он переваривает легко. Если залить в InfluxDB сырые данные, то база зависнет. Он может хранить данные по году и больше, если туда всё подряд не лить
Pandas хорош для вычислений в оперативной памяти, он загружает весь DataFrame в ОЗУ. Ему надо много ОЗУ, работает он быстро. Пробовал в бою. Если данные в ОЗУ не поместятся, то включится gc, обработка замедлится или вообще будет не возможна. На практике во время загрузки данных выполнялся их парсинг, чтобы сырые данные превратить в статистику, которая влежает в ОЗУ.
ElasticSearch не сжимает данные, имеет быстрый и удобный поисковый движок, но требует много места на диске под индексы. Поэтому там логи больше недели не хранят. Он для оперативного разбора данных за последнюю неделю.
InfluxDB хорош для хранения статистики, а не для сырых данных. В него загружаю статистику по логам - сколько было таких текстов (тегов) за 5 минут. А не все тексты за 5 минут. Статистику можно создать в awk, python + pandas, csvkit, чем-либо другом. Такой объем он переваривает легко. Если залить в InfluxDB сырые данные, то база зависнет. Он может хранить данные по году и больше, если туда всё подряд не лить
VG
да, бд инфлакса я уже вешал :)
значит стоит подумать в сторону эластика, наверное. Потому что мне логи анализировать интересно в ближайшее время после теста - что бы понять, что и как померло.
значит стоит подумать в сторону эластика, наверное. Потому что мне логи анализировать интересно в ближайшее время после теста - что бы понять, что и как померло.
KY
а чем плохо решение, когда при фейле семпла пишется респонс в инфлюкс через хттп, ему можно добавить айди закуска и семпл в котором был фейл. БД не распухает - я поставил жизнь на эту таблицу 2 недели, потом удаляется. проанализрвал с удобствами и все
ВС
а чем плохо решение, когда при фейле семпла пишется респонс в инфлюкс через хттп, ему можно добавить айди закуска и семпл в котором был фейл. БД не распухает - я поставил жизнь на эту таблицу 2 недели, потом удаляется. проанализрвал с удобствами и все
Здорово
KY
а логи приложений в ELK храним, в целом - довольно удобно
S
ELK хорош если нужен полнотекстовой поиск, из ещë плюсов есть kibana как gui.
В кх синтаксис sql запросов, что может быть проще чем кибана или lucene в elk.
В кх можно ttl также выставлять для данных чтобы ротировать.
Gui специфичные, но есть. Мы пишем в кх syslog-ом, а отображаем графаной.
В кх синтаксис sql запросов, что может быть проще чем кибана или lucene в elk.
В кх можно ttl также выставлять для данных чтобы ротировать.
Gui специфичные, но есть. Мы пишем в кх syslog-ом, а отображаем графаной.
KY
Solresl
ELK хорош если нужен полнотекстовой поиск, из ещë плюсов есть kibana как gui.
В кх синтаксис sql запросов, что может быть проще чем кибана или lucene в elk.
В кх можно ttl также выставлять для данных чтобы ротировать.
Gui специфичные, но есть. Мы пишем в кх syslog-ом, а отображаем графаной.
В кх синтаксис sql запросов, что может быть проще чем кибана или lucene в elk.
В кх можно ttl также выставлять для данных чтобы ротировать.
Gui специфичные, но есть. Мы пишем в кх syslog-ом, а отображаем графаной.
я смотрю тоже в сторону кх, но пока текущий стек не дает поводов попробовать
S
Если он устраивает, то и менять не стоит. ELK На малых объемах удобнее, на больших просто прожорливее.
2020 June 08
I
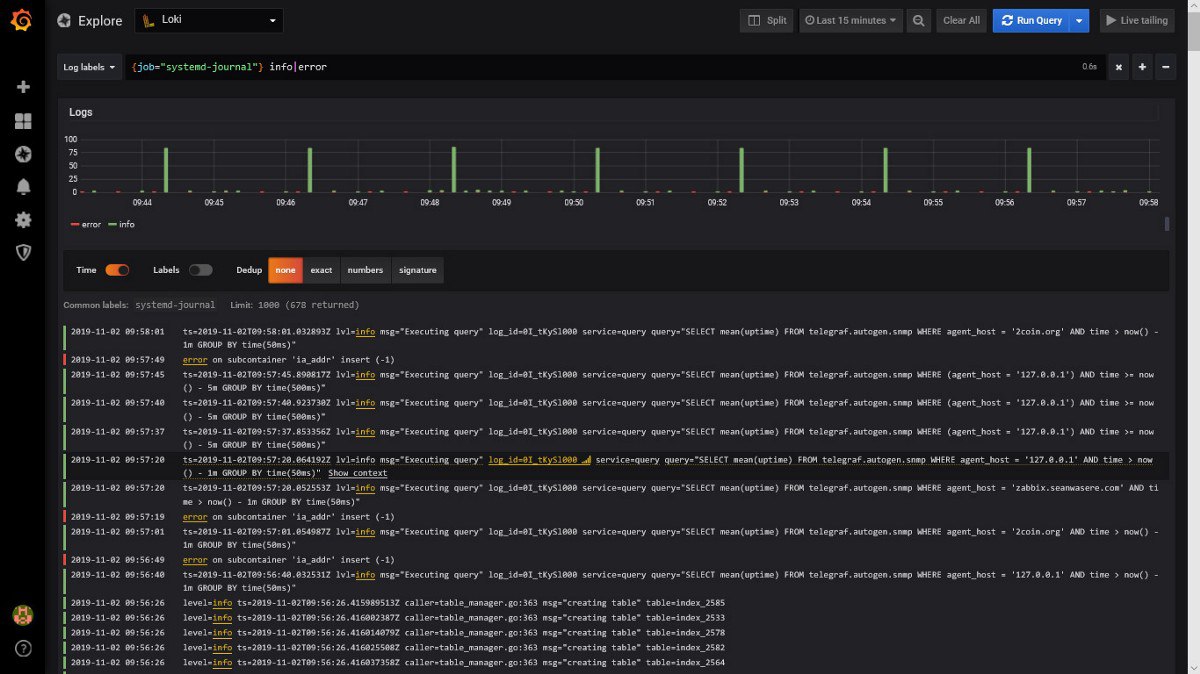
Кстати, есть удобные способы анализировать ошибки, проявившиеся в ходе теста Jmeter?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
Способ есть)
I
Кстати, есть удобные способы анализировать ошибки, проявившиеся в ходе теста Jmeter?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
Вот жеж он)
I
Кстати, есть удобные способы анализировать ошибки, проявившиеся в ходе теста Jmeter?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?

I
Кстати, есть удобные способы анализировать ошибки, проявившиеся в ходе теста Jmeter?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
Что есть: в Grafana вижу, что завалились 15% операций.
А причины - не вижу. То, что Jmeter передаёт через backendListner - бесполезная фигня.
Можно анализировать лог жметра, но если нам нужны ответы с сообщениями об ошибках - лог должен быть в xml, а вы знаете, как это классно - читать xml на пару мегабайт.
у Серпутко есть jsr223-листнер, который, вроде, умеет передавать в influx сами ошибки, но он требует установленной галочки "Create parent sempler", а с ней увеличивается расход памяти. Но я уже думаю перейти на этот вариант.
Чего хочется:
Что бы к логи тоже складывались в хранилище, откуда можно было читать информацию в Grafana, фильтруя по $TimeFilter или тредгруппам / транзакциям.
Вроде напрашивается передача логов в Elastic или парсинг их и передача в графану.
Но может уже есть готовые решения, что бы не пилить свои велосипеды?
I
Ну и сорт еще раз в конце)
I
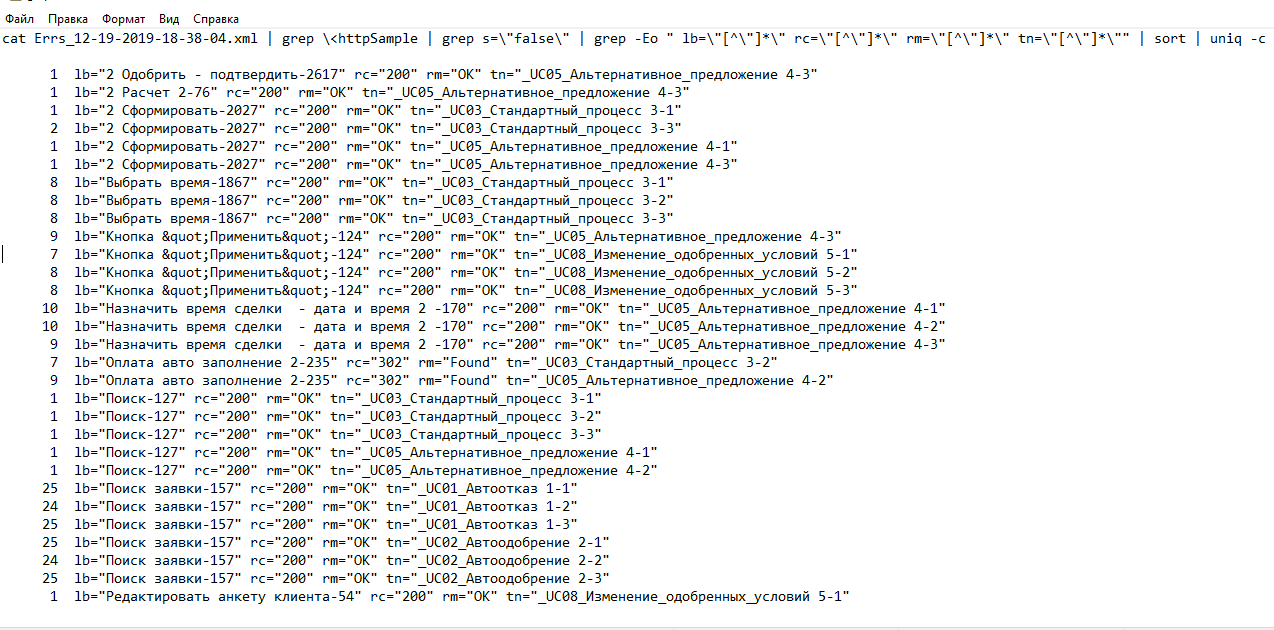
Тут получаем топ ошибок с их причинами.
Обработка файла xml логов лисенера, достаточно errors only.
Данные примеры не слишком показательны, потому что там текст ошибки был в теле ответа, а response code всегда 200.
Обычно код не 200, и в response message всё-таки есть информация полезная по ошибке.
Обработка файла xml логов лисенера, достаточно errors only.
Данные примеры не слишком показательны, потому что там текст ошибки был в теле ответа, а response code всегда 200.
Обычно код не 200, и в response message всё-таки есть информация полезная по ошибке.
VG
Тут получаем топ ошибок с их причинами.
Обработка файла xml логов лисенера, достаточно errors only.
Данные примеры не слишком показательны, потому что там текст ошибки был в теле ответа, а response code всегда 200.
Обычно код не 200, и в response message всё-таки есть информация полезная по ошибке.
Обработка файла xml логов лисенера, достаточно errors only.
Данные примеры не слишком показательны, потому что там текст ошибки был в теле ответа, а response code всегда 200.
Обычно код не 200, и в response message всё-таки есть информация полезная по ошибке.
Это для людей, консоль любят больше чем гуи
Мне же нужно парой кликов мышки с комфортом выделить нужный отрезок теста и увидеть, что именно в этот отрезок теста начали валиться эти операции.
У меня большинство тестов ступенчатые, и проблемы начинаются в определённом месте.
Ну и мне важно, сто при нагрузке в 120% валятся толькл операции X (не критичные), а при нагрузке 180% начали валиться все операции.
Но вообще за способ большое спасибо - я не воспринимал grep как инструмент анализа форматированного хмл, а зря.
Мне же нужно парой кликов мышки с комфортом выделить нужный отрезок теста и увидеть, что именно в этот отрезок теста начали валиться эти операции.
У меня большинство тестов ступенчатые, и проблемы начинаются в определённом месте.
Ну и мне важно, сто при нагрузке в 120% валятся толькл операции X (не критичные), а при нагрузке 180% начали валиться все операции.
Но вообще за способ большое спасибо - я не воспринимал grep как инструмент анализа форматированного хмл, а зря.
VG
а чем плохо решение, когда при фейле семпла пишется респонс в инфлюкс через хттп, ему можно добавить айди закуска и семпл в котором был фейл. БД не распухает - я поставил жизнь на эту таблицу 2 недели, потом удаляется. проанализрвал с удобствами и все
А как ты это сделал?
Я думал, что бэкенд листер пишет всё в одну таблицу
Я думал, что бэкенд листер пишет всё в одну таблицу