БЕ
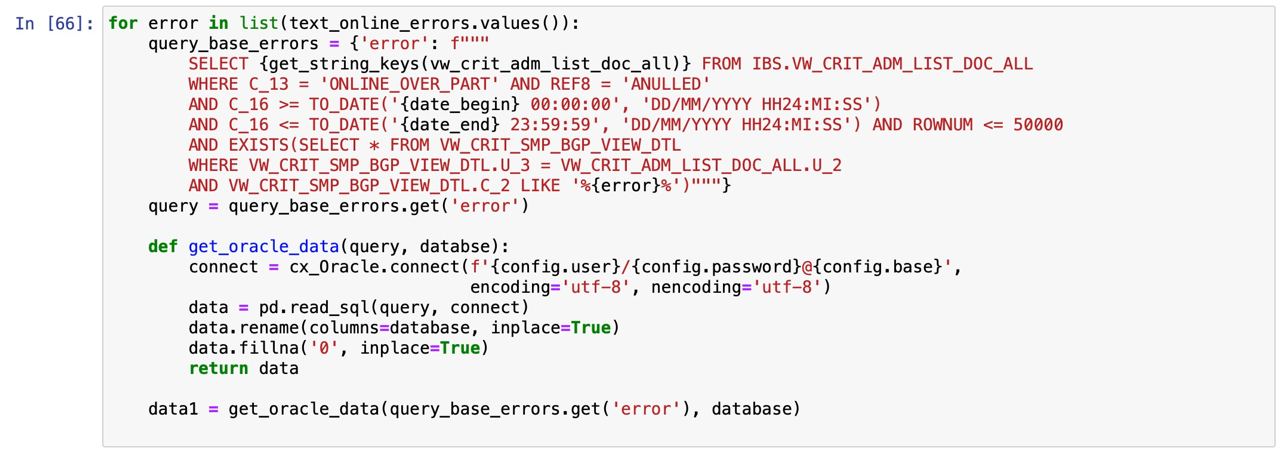
У меня есть словарь SQL запросов, где я подставляю список переменныех Дальше эти запросы подставляю в pd.read_sql, чтобы выгрузить из Oracle множество df. Затем df буду соединять. Это надумывал как раз для создания df, а дальше мерджить их...
Size: a a a
БЕ
БЕ
ND
АК
АК
АК
БЕ
АК
АК
АК
АК
АК
БЕ
АК
АК
dict_df = {'df_type_1':[], 'df_type_2':[]} data1 = get_orcale_data
dict_df_[df_type_number].append(get_oracle_data)
АК
БЕ
ES
АК
ES